Question: A partial adjustment model is / where y*
A partial adjustment model is
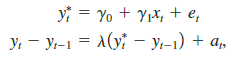
where y*t is the desired or optimal level of y and yt is the actual (observed) level. For example, y*t is the desired growth in firm inventories, and xt is growth in firm sales. The parameter g1 measures the effect of xt on y*t. The second equation describes how the actual y adjusts depending on the relationship between the desired y in time t and the actual y in time t – 1. The parameter l measures the speed of adjustment and satisfies 0 (i) Plug the first equation for ypt into the second equation and show that we can write
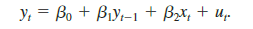
In particular, find the
Transcribed Image Text:
yi = Yo + Y1X, + e, Y. - Yt-1 = 1(yi – y-1) + a, y; = Bo + Biy:-1 + Bx, + u.
> Use CRIME4 for this exercise. (i) Reestimate the unobserved effects model for crime in Example 13.9 but use fixed effects rather than differencing. Are there any notable sign or magnitude changes in the coefficients? What about statistical significance?
> Use the data in COUNTYMURDERS to answer this question. The data set covers murders and executions (capital punishment) for 2,197 counties in the United States. (i) Consider the model where θt represents a different intercept for each time pe
> Use the data set in AIRFARE to answer this question. The estimates can be compared with those in Computer Exercise 10, in this Chapter. (i) Compute the time averages of the variable concen; call these concenbar. How many different time averages can there
> The data set DRIVING includes state-level panel data (for the 48 continental U.S. states) from 1980 through 2004, for a total of 25 years. Various driving laws are indicated in the data set, including the alcohol level at which drivers are considered leg
> Let invent be the real value inventories in the United States during year t, let GDPt denote real gross domestic product, and let r3t denote the (ex post) real interest rate on three-month T-bills. The ex post real interest rate is (approximately) r3t =
> Use the data in ELEM94_95 to answer this question. The data are on elementary schools in Michigan. In this exercise, we view the data as a cluster sample, where each school is part of a district cluster. (i) What are the smallest and largest number of sc
> This question assumes that you have access to a statistical package that computes standard errors robust to arbitrary serial correlation and heteroskedasticity for panel data methods. (i) For the pooled OLS estimates in Table 14.1, obtain the standard er
> Use the data in AIRFARE for this exercise. We are interested in estimating the model where log(fare) = n, + Biconcen + Bzlog(dist;) + B3[log(dist;) ]P + a; + uj, t = 1,..., 4,
> Use the data in RENTAL for this exercise. The data on rental prices and other variables for college towns are for the years 1980 and 1990. The idea is to see whether a stronger presence of students affects rental rates. The unobserved effects model is wh
> Use CRIME4 for this exercise. (i) Add the logs of each wage variable in the data set and estimate the model by first differencing. How does including these variables affect the coefficients on the criminal justice variables in Example 13.9? (ii) Do the w
> VOTE2 includes panel data on House of Representatives elections in 1988 and 1990. Only winners from 1988 who are also running in 1990 appear in the sample; these are the incumbents. An unobserved effects model explaining the share of the incumbentâ
> Use GPA3 for this exercise. The data set is for 366 student-athletes from a large university for fall and spring semesters. [A similar analysis is in Maloney and McCormick (1993), but here we use a true panel data set.] Because you have two terms of data
> Use CRIME3 for this exercise. (i) In the model of Example 13.6, test the hypothesis H0:
> Use the data in RENTAL for this exercise. The data for the years 1980 and 1990 include rental prices and other variables for college towns. The idea is to see whether a stronger presence of students affects rental rates. The unobserved effects model is w
> Use the data in INJURY for this exercise. (i) Using the data for Kentucky, reestimate equation (13.12), adding as explanatory variables male, married, and a full set of industry and injury type dummy variables. How does the estimate on afchnge . highearn
> Add a linear time trend to equation (11.27). Is a time trend necessary in the first-difference equation? (ii) Drop the time trend and add the variables ww2 and pill to (11.27) (do not difference these dummy variables). Are these variables jointly signifi
> Use the data in KIELMC for this exercise. (i) The variable dist is the distance from each home to the incinerator site, in feet. Consider the model If building the incinerator reduces the value of homes closer to the site, what is the sign of d1? What do
> Use the data in CPS78_85 for this exercise. (i) How do you interpret the coefficient on y85 in equation (13.2)? Does it have an interesting interpretation? (ii) Holding other factors fixed, what is the estimated percent increase in nominal wage for a ma
> Use the data in COUNTYMURDERS to answer this question. The data set covers murders and executions (capital punishment) for 2,197 counties in the United States. (i) Find the average value of murdrate across all counties and years. What is the standard dev
> The data set HAPPINESS contains independently pooled cross sections for the even years from 1994 through 2006, obtained from the General Social Survey. The dependent variable for this problem is a measure of “happiness,” vhappy, which is a binary variabl
> Use the data in JTRAIN3 for this question. (i) Estimate the simple regression model re78 =
> Use the data in WAGEPAN for this exercise. (i) Consider the unobserved effects model where ai is allowed to be correlated with educi and unionit. Which parameters can you estimate using first differencing? (ii) Estimate the equation from part (i) by FD,
> Use the data in MURDER for this exercise. (i) Using the years 1990 and 1993, estimate the equation by pooled OLS and report the results in the usual form. Do not worry that the usual OLS standard errors are inappropriate because of the presence of ai. Do
> The file MATHPNL contains panel data on school districts in Michigan for the years 1992 through 1998. It is the district-level analogue of the school-level data used by Papke (2005). The response variable of interest in this question is math4, the percen
> For this exercise, we use JTRAIN to determine the effect of the job training grant on hours of job training per employee. The basic model for the three years is (i) Estimate the equation using first differencing. How many firms are used in the estimation
> Use the data in FERTIL1 for this exercise. (i) In the equation estimated in Example 13.1, test whether living environment at age 16 has an effect on fertility. (The base group is large city.) Report the value of the F statistic and the p-value. (ii) Test
> Use the data in PHILLIPS for this exercise, but only through 1996. (i) We assumed that the natural rate of unemployment is constant. An alternative form of the expectations augmented Phillips curve allows the natural rate of unemployment to depend on pas
> The file FISH contains 97 daily price and quantity observations on fish prices at the Fulton Fish Market in New York City. Use the variable log(avgprc) as the dependent variable. (i) Regress log(avgprc) on four daily dummy variables, with Friday as the b
> Use the data in TRAFFIC2 for this exercise. (i) Run an OLS regression of prcfat on a linear time trend, monthly dummy variables, and the variables wkends, unem, spdlaw, and beltlaw. Test the errors for AR(1) serial correlation using the regression in equ
> (i) Use the data in BARIUM, obtain the iterative Cochrane-Orcutt estimates. (ii) Are the Prais-Winsten and Cochrane-Orcutt estimates similar? Did you expect them to be?
> (i) In Computer Exercise C7 in Chapter 10, you estimated a simple relationship between consumption growth and growth in disposable income. Test the equation for AR(1) serial correlation (using CONSUMP). (ii) In Computer Exercise C7 in Chapter 11, you tes
> Consider the version of Fair’s model in Example 10.6. Now, rather than predicting the proportion of the two-party vote received by the Democrat, estimate a linear probability model for whether or not the Democrat wins. (i) Use the binar
> (i) Use NYSE to estimate equation (12.48). Let â„Ž t be the fitted values from this equation (the estimates of the conditional variance). How many â„Ž t are negative? (ii) Add return2t21 to (12.48) and again compute the
> (i) In part (1) of Computer Exercise C6 in Chapter 11, you were asked to estimate the accelerator model for inventory investment. Test this equation for AR(1) serial correlation. 1) Use the data in INVEN to estimate the accelerator model. Report the resu
> (i) Using the data in WAGEPRC, estimate the distributed lag model by Using regression given below to test for AR(1) serial correlation. (ii) Reestimate the model using iterated Cochrane-Orcutt estimation. What is your new estimate of the long-run propen
> Use the data in MINWAGE for this exercise, focusing on sector 232. (i) Estimate the equation and test the errors for AR(1) serial correlation. Does it matter whether you assume gmwaget and gcpit are strictly exogenous? What do you conclude overall? (ii)
> Use the data in OKUN to answer this question; see also Computer Exercise C11 in Chapter 11. (i) Estimate the equation pcrgdpt =
> It may be that the expected value of the return at time t, given past returns, is a quadratic function of return-1. To check this possibility, use the data in NYSE to estimate report the results in standard form. (ii) State and test the null hypothesis t
> Use the data in INVEN for this exercise; see also Computer Exercise C6 in Chapter 11. (i) Obtain the OLS residuals from the accelerator model ∆invent =
> Use the data in NYSE to answer these questions. (i) Estimate the model in equation (12.47) and obtain the squared OLS residuals. Find the average, minimum, and maximum values of
> Use the data in PHILLIPS to answer these questions. (i) Using the entire data set, estimate the static Phillips curve equation inft =
> we estimated a finite DL model in first differences (changes): Use the data in FERTIL3 to test whether there is AR(1) serial correlation in the errors. cgfr, 3 Yo + dосре, + бусре, -1 + бәсре, -2 + и,.
> Use the data in APPROVAL to answer the following questions. See also Computer Exercise C14 in Chapter 11. (i) Estimate the equation using first differencing and test the errors in the first-differenced (FD) equation for AR(1) serial correlation. In par
> Use the data in BARIUM to answer this question. (i) In Table 12.1 the reported standard errors for OLS are uniformly below those of the corresponding standard errors for GLS (Prais-Winsten). Explain why comparing the OLS and GLS standard errors is flawed
> Use the data in APPROVAL to answer the following questions. (i) Compute the first order autocorrelations for the variables approve and lrgasprice. Do they seem close enough to unity to worry about unit roots? (ii) Consider the model where the first two
> Use the data in BEVERIDGE to answer this question. The data set includes monthly observations on vacancy rates and unemployment rates for the United States from December 2000 through February 2012. (i) Find the correlation between urate and urate_1. Woul
> Use the data in HSEINV for this exercise. (i) Find the first order autocorrelation in log(invpc). Now, find the autocorrelation after linearly detrending log(invpc). Do the same for log(price). Which of the two series may have a unit root? (ii) Based on
> Suppose that the equation satisfies the sequential exogeneity assumption in equation (11.40). (i) Suppose you difference the equation to obtain How come applying OLS on the differenced equation does not generally result in consistent estimators of the
> Use the data in MINWAGE for this exercise, focusing on the wage and employment series for sector 232 (Men’s and Boys’ Furnishings). The variable gwage232 is the monthly growth (change in logs) in the average wage in se
> Let hy6t denote the three-month holding yield (in percent) from buying a six-month T-bill at time 1t 2 12 and selling it at time t (three months hence) as a three-month T-bill. Let hy3t-1 be the three month holding yield from buying a three-month T-bill
> For the U.S. economy, let gprice denote the monthly growth in the overall price level and let gwage be the monthly growth in hourly wages. [These are both obtained as differences of logarithms: gprice = ∆log(price) and gwage = â&#
> Let {yt: t = 1, 2,….} follow a random walk, as in (11.20), with y0 = 0. Show that for t ≥ 1, h > 0. Corr(y, Yt+h) = /(t + h) Y: = yt-1 + e, t = 1, 2, ..., [11.20]
> Suppose that a time series process {yt} is generated by yt = z + et, for all t = 1, 2,…. , where {et} is an i.i.d. sequence with mean zero and variance σ2e. The random variable z does not change over time; it has mean zero and variance σ2e. Assume that e
> Let {et: t = -1, 0, 1, ……} be a sequence of independent, identically distributed random variables with mean zero and variance one. Define a stochastic process by xt = et – (1/2)et-1 + (1/2)et-2, t = 1, 2,……. (i) Find E(xt) and Var(xt). Do either of these
> Let {xt: t = 1, 2,…….} be a covariance stationary process and define
> Suppose you want to test whether girls who attend a girls’ high school do better in math than girls who attend coed schools. You have a random sample of senior high school girls from a state in the United States, and score is the score on a standardized
> The following is a simple model to measure the effect of a school choice program on standardized test Performance where score is the score on a statewide test, choice is a binary variable indicating whether a student attended a choice school in the last
> (i) In the model with one endogenous explanatory variable, one exogenous explanatory variable, and one extra exogenous variable, take the reduced form for y2 (15.26), and plug it into the structural equation (15.22). This gives the reduced form for y1: F
> Okun’s Law—see, for example, Mankiw (1994, Chapter 2)—implies the following relationship between the annual percentage change in real GDP, pcrgdp, and the change in the annual unemployment rate, cunem: pcrgdp = 3 - 2 . cunem. If the unemployment rate is
> Define the growth in hourly wage and output per hour as the change in the natural log: ghrwage = ∆log(hrwage) and goutphr = ∆log(outphr). Consider a simple extension of the model estimated This allows an increase in pr
> What are the relative advantages and disadvantages of being able to observe covertly a focus group discussion?
> Why is the focus group moderator so important to the success of a focus group discussion?
> To what extent can a moderator achieve an ‘objective detachment’ from a focus group discussion?
> What does a ‘comfortable setting’ mean in the context of running a focus group?
> Evaluate the purpose of running an experimental focus group discussion.
> What determines the questions, issues and probes used in a focus group?
> What are the difficulties in conducting focus groups with managers or professionals?
> What are the key benefits and drawbacks of conducting focus group discussions?
> What is a Marketing Research Online Community (MROC)? How can an MROC be viewed as a group-based qualitative research technique?
> Describe the opportunities and difficulties that may occur if alcoholic drinks are served during focus group discussions.
> What arguments can be used by sceptics of marketing research?
> What is an online focus group? What are the distinct advantages and disadvantages of running online compared with traditional focus groups?
> Describe the purpose and benefits of using stimulus material in a focus group.
> What determines the number of focus groups that should be undertaken in any research project?
> What can the researcher do to make potential participants want to take part in a focus group?
> Why may researchers not wish to fully reveal the purpose of a focus group discussion with participants before it starts?
> Why may marketing decision makers wish to understand the context of consumption?
> What is netnography? What additional consumer insights can netnography deliver?
> What does ethnographic research aim to achieve in the study of consumers?
> What role does theory play in the approaches adopted by positivist and interpretivist researchers?
> In what ways may the positivist and the interpretivist view potential research participants?
> Explain why there may be the need for iterations between stages of the marketing-research process.
> Describe the characteristics of positivist and interpretivist researchers.
> Evaluate the differences between a European and an American approach to qualitative research.
> Why is it not always possible or desirable to use quantitative marketing research techniques?
> What do you see as the key advantages and challenges of conducting qualitative research online?
> Describe the key elements to be balanced in the application of action research.
> What does ‘listening’ mean for the qualitative researcher? How may researchers ‘listen’ to consumers?
> Is it possible for researchers to be objective?
> What stages are involved in the application of a grounded theory approach?
> Describe and illustrate two research techniques that may be utilised in ethnographic research.
> What criticisms do qualitative researchers make of the approaches adopted by quantitative researchers, and vice versa?
> Describe the steps in the marketing-research process.
> How may the data from web analytics support the practice of marketing research?
> How may data from customer relationship management systems support the practice of marketing research?
> What is a geodemographic classification of consumers?
> Why may the characteristics of consumers differ, based upon where they live?
> Describe the benefits to the researcher of being able to capture data that identify characteristics of consumers and their shopping behaviour in a store.
> Describe the benefits to the marketing decision maker of being able to capture data that identify characteristics of consumers and their shopping behaviour in a store.
> What other sources, beyond electronic scanner devices, electronically observe customer behaviour?

