Question: A random sample of 100 20-year-
A random sample of 100 20-year-old men is selected from a population and these men’s height and weight are recorded. A regression of weight on height yields
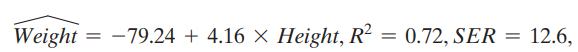
where Weight is measured in pounds and Height is measured in inches.
a. What is the regression’s weight prediction for someone who is 64 inches tall? 68 inches tall? 72 inches tall?
b. A man has a late growth spurt and grows 2 inches over the course of a year. What is the regression’s prediction for the increase in this man’s weight?
c. Suppose that instead of measuring weight and height in pounds and inches, these variables are measured in centimetres and kilograms. What are the regression estimates from this new centimetre–kilogram regression?
> Determine the missing amount for each of the following:
> The total assets and total liabilities (in millions) of Dollar Tree Inc. and Target Corporation follow: Determine the stockholders’ equity of each company.
> Using the income statement for Zenith Travel Service shown in Practice Exercise 1-4B, prepare a statement of owner’s equity for the year ended August 31, 20Y4. Megan Cox, the owner, invested an additional $43,200 in the business during
> The following revenue transactions occurred during August: Aug. 4. Issued Invoice No. 162 to Oasis Enterprises Co. for services provided on account, $320. 15. Issued Invoice No. 163 to City Electric Inc. for services provided on account, $535. 25. Issued
> Refer to the table of estimated regressions, computed using data on employees in a developing country. The data set consists of information on over 10,000 full-time, full-year workers. The highest educational achievement for each worker is either a high
> Refer to the table of estimated regressions, computed using data on employees in a developing country. The data set consists of information on over 10,000 full-time, full-year workers. The highest educational achievement for each worker is either a high
> Refer to the table of estimated regressions, computed using data on employees in a developing country. The data set consists of information on over 10,000 full-time, full-year workers. The highest educational achievement for each worker is either a high
> Refer to the table of estimated regressions, computed using data on employees in a developing country. The data set consists of information on over 10,000 full-time, full-year workers. The highest educational achievement for each worker is either a high
> Refer to the table of estimated regressions, computed using data on employees in a developing country. The data set consists of information on over 10,000 full-time, full-year workers. The highest educational achievement for each worker is either a high
> Equations (7.13) and (7.14) show two formulas for the homoskedasticity-only F-statistic. Show that the two formulas are equivalent. Data from Equation 7.13: Data from Equation 7.14:
> Refer to the table of estimated regressions, computed using data on employees in a developing country. The data set consists of information on over 10,000 full-time, full-year workers. The highest educational achievement for each worker is either a high
> (Yi, X1i, X2i) satisfy the assumptions. You are interested in b1, the causal effect of X1 on Y. Suppose X1 and X2 are uncorrelated. You estimate 1 by regressing Y onto X1 (so that X2 is not included in the regression). Does this estimator suffer from om
> A government study found that people who eat chocolate frequently weigh less than people who don’t. Researchers questioned 1000 individuals from Cairo between the ages of 20 and 85 about their eating habits, and measured their weight and height. On avera
> Critique each of the following proposed research plans. Your critique should explain any problems with the proposed research and describe how the research plan might be improved. Include a discussion of any additional data that need to be collected and t
> X and Y are discrete random variables with the following joint distribution: That is, Pr (X = 3, Y = 2) = 0.04, and so forth. a. Calculate the probability distribution, mean, and variance of Y. b. Calculate the probability distribution, mean, and varianc
> A researcher plans to study the causal effect of a strong legal system on the number of scandals in a country, using data from a random sample of countries in Asia. The researcher plans to regress the number of scandals on how strong a legal system is in
> Data were collected from a random sample of 200 home sales from a community in 2013. Let Price denote the selling price (in $1000s), BDR denote the number of bedrooms, Bath denote the number of bathrooms, Hsize denote the size of the house (in square fee
> Refer to the table of estimated regressions, computed using data for 2015 from the Current Population Survey. The data set consists of information on 7178 full-time, full-year workers. The highest educational achievement for each worker was either a high
> Refer to the table of estimated regressions, computed using data for 2015 from the Current Population Survey. The data set consists of information on 7178 full-time, full-year workers. The highest educational achievement for each worker was either a high
> Refer to the table of estimated regressions, computed using data for 2015 from the Current Population Survey. The data set consists of information on 7178 full-time, full-year workers. The highest educational achievement for each worker was either a high
> A school district undertakes an experiment to estimate the effect of class size on test scores in second-grade classes. The district assigns 50% of its previous year’s first graders to small second-grade classes (18 students per classroom) and 50% to reg
> Consider the regression model Yi = 1X1i + 2X2i + ui for i = 1, ……, n. Following analysis a. Specify the least squares function that is minimized by OLS. b. Compute the partial de
> (Yi, X1i, X2i) satisfy the assumption; in addition, var (ui | X1i, X2) = 4 and var (X1i) = 6. A random sample of size n = 400 is drawn from the population. a. Assume that X1 and X2 are uncorrelated. Compute the variance of ^1. b. Assume that corr (X1,
> Refer to the table of estimated regressions, computed using data for 2015 from the Current Population Survey. The data set consists of information on 7178 full-time, full-year workers. The highest educational achievement for each worker was either a high
> Consider the regression model Yi = Xi + ui, where ui and Xi satisfy the least squares assumptions. Let denote an estimator of b that is constructed as = Y>X, where Y and X are the sample means of Yi and Xi, respectively. a. Show that is a linear f
> The random variable Y has a mean of 4 and a variance of 1/9. Let Z = 3 (Y – 4). Find the mean and the variance of Z.
> Suppose (Yi, Xi) satisfy the least squares assumptions in Key Concept 4.3 and, in addition, ui is N (0, 2u) and is independent of Xi. A sample of size n = 30 yields where the numbers in parentheses are the homoskedastic-only standard er
> Suppose (Yi, Xi) satisfy the least squares assumptions. A random sample of size n = 250 is drawn and yields Y^ = 5.4 + 3.2X, R2 = 0.26, SER = 6.2. (3.1) (1.5) a. Test H0: 1 = 0 vs. H1: 1 ≠ 0 at the 5% level. b. Construct a 95% confidence interval for
> Refer to the regression described in Exercise 5.5. a. Do you think that the regression errors are plausibly homoskedastic? Explain. b. SE (^1) was computed using Equation. Suppose the regression errors were homoskedastic. Would this aff
> In the 1980s, Tennessee conducted an experiment in which kindergarten students were randomly assigned to “regular” and “small” classes and given standardized tests at the end of the
> Read the box “The Economic Value of a Year of Education: Homoskedasticity or Heteroskedasticity?”. Use the regression reported in Equation (5.23) to answer the following. a. A randomly selected 30-year-old worker repor
> Suppose a random sample of 100 25-year-old men is selected from a population and their heights and weights are recorded. A regression of weight on height yields where Weight is measured in pounds and Height is measured in inches. One man has a late growt
> Suppose that a researcher, using wage data on 200 randomly selected male workers and 240 female workers, estimates the OLS regression where Wage is measured in dollars per hour and Male is a binary variable that is equal to 1 if the person is a male and
> A researcher has two independent samples of observations on (Yi, Xi). To be specific, suppose Yi denotes earnings, Xi denotes years of schooling, and the independent samples are for men and women. Write the regression for men as Ym,i = 
> Suppose Yi = Xi + ui, where (ui, Xi) satisfy the Gauss–Markov conditions. a. Derive the least squares estimator of b, and show that it is a linear function of Y1, ……, Yn. b. Show that the estimator is conditionally unbiased. c. Derive the conditional va
> Suppose (Yi, Xi) satisfy the least squares assumptions in Key Concept 4.3 and, in addition, ui is distributed N (0, 2u) and is independent of Xi. a. Is ^1 conditionally unbiased? b. Is ^1 the best linear conditionally unbiased estimator of 1? c. How
> In a given population of two-earner male-female couples, male earnings have a mean of $50,000 per year and a standard deviation of $15,000. Female earnings have a mean of $48,000 per year and a standard deviation of $13,000. The correlation between male
> Derive the variance of b^0 under homoscedasticity given in Equation (5.28). Data from Equation 5.28:
> A random sample of workers contains nm = 100 men and nw = 150 women. The sample average of men’s weekly earnings is €565.89, and the standard deviation; is €75.62. The corresponding values for women are
> Let Xi denote a binary variable, and consider the regression Yi = 0 + 1Xi + ui. Let Y0 denote the sample mean for observations with X = 0, and let Y1 denote the sample mean for observations with X = 1. Show that ^0 = Y0, ^0 + ^1 = Y1, and ^1 = Y1 -
> Suppose a researcher, using data on class size (CS) and average test scores from 50 third-grade classes, estimates the OLS regression a. Construct a 95% confidence interval for b1, the regression slope coefficient. b. Calculate the p-value for the two-si
> a. A linear regression yields ^1 = 0. Show that R2 = 0. b. A linear regression yields R2 = 0. Does this imply that ^1 = 0?
> Suppose all of the regression assumptions in Key Concept 4.3 are satisfied except that the first assumption is replaced with E (ui | Xi) = 2. Which parts of Key Concept 4.4 continue to hold? Which change? Why? (Is ^1 normally distributed in large sampl
> Show that ^0 is an unbiased estimator of 0.
> Show that the first least squares assumption, E (ui | Xi) = 0, implies that E (Yi | Xi) = 0 + 1Xi.
> A researcher runs an experiment to measure the impact of a short nap on memory. There are 200 participants and they can take a short nap of either 60 minutes or 75 minutes. After waking up, each participant takes a short test for short-term recall. Each
> Your class is asked to investigate the effect of average temperature on average weekly earnings (AWE, measured in dollars) across countries, using the following general regression approach: One of your classmates, Rachel, is an American and decides to an
> The following table gives the joint probability distribution between employment status and college graduation among those either employed or looking for work (unemployed) in the working-age population of South Africa. a. Compute E(Y). b. The unemployment
> A regression of average monthly expenditure (AME, measured in dollars) on average monthly income (AMI, measured in dollars) using a random sample of college educated full-time workers earning €100 to €1.5 million yields
> A sample (Xi, Yi), i = 1, ……, n, is collected from a population with E (Y X) = 0 + 1X and used to compute the least squares *estimators ^0 and 
> Show that the sample regression line passes through the point (X, Y).
> Suppose Yi = 0 + 1Xi + ui, where  is a nonzero constant and (Yi, Xi) satisfy the three least squares assumptions. Show that the large-sample variance of n1 is giv
> a. Show that the regression R2 in the regression of Y on X is the squared value of the sample correlation between X and Y. That is, show that R2 = r2XY. b. Show that the R2 from the regression of Y on X is the same as the R2 from the regression of X on
> Consider the regression model Yi = 0 + 1Xi + ui. a. Suppose you know that 0 = 0. Derive a formula for the least squares estimator of 1. b. Suppose you know that 0 = 4. Derive a formula for the least squares estimator of 1.
> Suppose Yi = 0 + 1Xi + ui, where (Xi, ui) are i.i.d. and Xi is a Bernoulli random variable with Pr (X = 1) = 0.30. When X = 1, ui is N (0, 3); when X = 0, ui is N (0, 2). a. Show that the regression assumptions in Key Concept 4.3 are satisfied. b. Deri
> Suppose that a researcher, using data on class size (CS) and average test scores from 50 third-grade classes, estimates the OLS regression: a. A classroom has 25 students. What is the regression’s prediction for that classroomâ
> Suppose that a plant manufactures integrated circuits with a mean life of 1000 hours and a standard deviation of 100 hours. An inventor claims to have developed an improved process that produces integrated circuits with a longer mean life and the same st
> In July, Lugano’s, a city in Switzerland, daily high temperature has a mean of 65oF and a standard deviation of 5oF. What are the mean, standard deviation, and variance in degrees Celsius?
> A new version of the SAT is given to 1500 randomly selected high school seniors. The sample mean test score is 1230, and the sample standard deviation is 145. Construct a 95% confidence interval for the population mean test score for high school seniors.
> In a given population, 50% of the likely voters are women. A survey using a simple random sample of 1000 landline telephone numbers finds 55% women. Is there evidence that the survey is biased? Explain.
> Let Y1 ……, Yn be i.i.d. draws from a distribution with mean m. A test of H0: = 10 vs. H1: ≠ 10 using the usual t-statistic yields a p-value of 0.07. a. Does the 90% confidence interval contain m = 10? Explain. b. Can you determine if = 8 is contain
> A survey of 1000 registered voters are conducted, and the voters are asked to choose between candidate A and candidate B. Let p denote the fraction of voters in the population who prefer candidate A, and let p^ denote the fraction of voters in the sample
> Using the data in Exercise 3.3: a. Construct a 95% confidence interval for p. b. Construct a 99% confidence interval for p. c. Why is the interval in (b) wider than the interval in (a)? d. Without doing any additional calculations, test the hypothesis H0
> In a poll of 500 likely voters, 270 responded that they would vote for the candidate from the democratic party, while 230 responded that they would vote for the candidate from the republican party. Let p denote the fraction of all likely voters who prefe
> Suppose Yi∼ i.i.d. N (Y, 2Y) for i = 1, ……, n. With 2Y known, the t-statistic for testing H0: Y = 0 vs. H1: 
> Show that the pooled standard error [SEpooled (Ym – Yw)] given following Equation (3.23) equals the usual standard error for the difference in means in Equation (3.19) when the two group sizes are the same (nm = nw). Data from Equation
> Suppose (Xi, Yi) are i.i.d. with finite fourth moments. Prove that the sample covariance is a consistent estimator of the population covariance; that is where sXY is defined in Equation (3.24). Data from Equation 3.24:
> Let Y be a Bernoulli random variable with success probability Pr (Y = 1) = p, and let Y1, ……, Yn be i.i.d. draws from this distribution. Let p^ be the fraction of successes (1s) in this sample. a. Show that p^ = Y. b. Show that p^ is an unbiased estimato
> Suppose X is a Bernoulli random variable with Pr (X = 1) = p. a. Show E(X4) = p. b. Show E(Xk) = p for k > 0. c. Suppose that p = 0.53. Compute the mean, variance, skewness, and kurtosis of X.
> a. Y is an unbiased estimator of Y. Is Y2 an unbiased estimator of 2Y? b. Y is a consistent estimator of Y. Is Y2 a consistent estimator of 2Y?
> This exercise shows that the sample variance is an unbiased estimator of the population variance when Y1, ……, Yn are i.i.d. with mean Y and variance 2Y. a. Show that b. Show that
> Read the box “Social Class or Education? Childhood Circumstances and Adult Earnings Revisited”. a. Construct a 95% confidence interval for the difference in the household earnings of people whose father NS-SEC classification was higher between those with
> Assume that grades on a standardized test are known to have a mean of 500 for students in Europe. The test is administered to 600 randomly selected students in Ukraine; in this sample, the mean is 508, and the standard deviation (s) is 75. a. Construct a
> Ya and Yb are Bernoulli random variables from two different populations, denoted a and b. Suppose E (Ya) = pa and E (Yb) = pb. A random sample of size na is chosen from population a, with a sample average denoted p^a, and a random sample of size nb is ch
> Values of height in inches (X) and weight in pounds (Y) are recorded from a sample of 200 male college students. The resulting summary statistics are X = 71.2 in., Y = 164 lb, sX = 1.9 in., sY = 16.4 lb, sXY = 22.54 in. * lb, and rXY = 0.8. Convert these
> Data on fifth-grade test scores (reading and mathematics) for 400 school districts in Brussels yield average score Y = 712.1 and standard deviation sY = 23.2. a. Construct a 90% confidence interval for the mean test score in the population. b. When the d
> To investigate possible gender discrimination in a British firm, a sample of 120 men and 150 women with similar job descriptions are selected at random. A summary of the resulting monthly salaries follows: a. What do these data suggest about wage differe
> Consider the estimator Y∼, defined in Equation (3.1). Show that (a) E (Y∼) = Y and (b) var (Y∼) = 1.252Y / n. Data from Equation 3.1:
> Suppose a new standardized test is given to 150 randomly selected third-grade students in Amsterdam. The sample average score Y on the test is 42 points, and the sample standard deviation, sY, is 6 points. a. The authors plan to administer the test to al
> Using the random variables X and Y from Table 2.2, consider two new random variables, W = 4 + 8X and V = 11 - 2Y. Compute (a) E(W) and E(V); (b) 2W and 2V; and (c) WV and corr (W, V).
> In a population, Y = 75 and 2Y = 45. Use the central limit theorem to answer the following questions: a. In a random sample of size n = 50, find Pr (Y < 73). b. In a random sample of size n = 90, find Pr (76 < Y < 77) c. In a random sample of size n =
> For the conditional distribution of the number of network failures M given network age A. Let Pr(A=0) = 0.5; that is, you work in your room 50% of the time. a. Compute the probability of three network failures, Pr (M = 3). b. Use Bayes’ rule to compute P
> Consider the problem of predicting Y using another variable, X, so that the prediction of Y is some function of X, say g(X). Suppose that the quality of the prediction is measured by the squared prediction error made on average over all predictions, that
> Suppose that Y1, Y2, ……, Yn are random variables with a common mean Y; a common variance 2Y; and the same correlation  (so that the correlation between Yi and Yj
> Let x1, ……, xn denote a sequence of numbers; y1, ……, yn denote another sequence of numbers; and a, b, and c denote three constants. Show that
> This exercise shows that the OLS estimator of a subset of the regression coefficients is consistent under the conditional mean independence assumption stated in Key Concept 6.6. Consider the multiple regression model in matrix form Where X and W, are, re
> Consider the regression model Yi = b0 + b1Xi + ui, where u1 = u∼1 and ui = 0.5ui - 1 + u∼i for i = 2, 3 … n. Suppose that u∼i are i.i.d. with mean 0 and variance 1 and are di
> Consider the regression model Yi = b1Xi + b2Wi + ui, where for simplicity the intercept is omitted and all variables are assumed to have a mean of 0. Suppose that Xi is distributed independently of (Wi, ui) but Wi and ui might be correlated, and let b^1
> Consider the regression model in matrix form, Y = X + W + U, where X is an n * k1 matrix of regressors and W is an n * K2 matrix of regressors. Then, as shown in Exercise 19.17, the OLS estimator ^ ca
> Let PX and MX be as defined in Equations (19.24) and (19.25). a. Prove that PXMX = 0n * n and that PX and MX are idempotent. b. Derive Equations (19.27) and (19.28). c. Show that rank (PX) = k + 1 and rank (MX) = n - k – 1. Data from E
> Consider the regression model Yi = 0 + 1Xi + ui from Chapter 4, and assume that the least squares assumptions in Key Concept 4.3 hold. a. Write the model in the matrix form given in Equations (19.2) and (19.3). b. Show
> Let W be an m * 1 vector with covariance matrix Σw, where Σw is finite and positive definite. Let c be a non-random m * 1 vector, and let Q = c′W. a. Show that b. Suppose that c ≠0m. Show tha
> Suppose that a sample of n = 20 households has the sample means and sample covariances below for a dependent variable and two regressors: a. Calculate the OLS estimates of 0, 1, and 2. Calculate ï
> Consider the homoskedastic linear regression model with two regressors, and let rX1, X2 = corr(X1, X2). Show that as n increases.
> Consider the regression model in matrix form Y = XB + WG + U, where X and W, are matrices of regressors and B and G are vectors of unknown regression coefficients. Let X∼ = MWX and Y ∼ = MWY, where MW = I â&#
> Suppose Yi is distributed i.i.d. N (0, 2) for i = 1, 2, …, n. a. Show that E (Y2i /ï€ ï³2) = 1 b. Show that c. Show that E(W) = n d. Show that
> This exercise takes up the problem of missing data discussed in Section 9.2. Consider the regression model Yi = Xib + ui, i = 1 … n, where all variables are scalars and the constant term/intercept is omitted for convenience. a. Suppos
> Consider the panel data model Yit = Xit + i + uit, where all variables are scalars. Assume that assumptions 1, 2, and 4 in Key Concept 10.3 hold and strengthen assumption 3, so that Xit and uit have eight nonzero fini
> Consider the regression model Y = XB + U. Partition X as [X1 X2] and B as [B′1 B′2]′, where X1 has k1 columns and X2 has k2 columns. Suppose that X′ 2 Y = k2 * 1. Let R = [(k0k1 * k)
> Consider the problem of minimizing the sum of squared residuals, subject to the constraint that Rb = r, where R is q * (k + 1) with rank q. Let B∼ be the value of b that solves the constrained minimization problem. a. Show that the La

