Question: Does first differencing reduce autocorrelation?
Does first differencing reduce autocorrelation? Consider the models
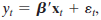
where
/
Compare the autocorrelation of ï¥t in the original model with that of vt in /
where
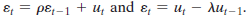
> Reverse regression continued. This and the next exercise continue the analysis of Exercise 2. In Exercise 2, interest centered on a particular dummy variable in which the regressors were accurately measured. Here we consider the case in which the crucial
> A regression model with K = 16 independent variables is fit using a panel of seven years of data. The sums of squares for the seven separate regressions and the pooled regression are shown below. The model with the pooled data allows a separate constant
> Prove that under the hypothesis that RB = q, the estimator where J is the number of restrictions, is unbiased for s2.
> Use the test statistic defined in Exercise 7 to test the hypothesis in Exercise 1.
> An alternative way to test the hypothesis RB - q = 0 is to use a Wald test of the hypothesis that L* = 0, where L* is defined in (5-23). Prove that Note that the fraction in brackets is the ratio of two estimators of s2. By virtue of (5-28) and the prece
> Prove the result that the R2 associated with a restricted least squares estimator is never larger than that associated with the unrestricted least squares estimator. conclude that imposing restrictions never improves the fit of the regression.
> Prove the result that the restricted least squares estimator never has a larger covariance matrix than the unrestricted least squares estimator.
> The expression for the restricted coefficient vector in (5-23) may be written in the form b* = [I - CR]b + w, where w does not involve b. What is C? show that the covariance matrix of the restricted least squares estimator is s2(X'X)-1 - s2(X'X)-1R'[R(X'
> The regression model to be analyzed is y = X1B1 + X2B2 + E , where X1 and X2 have K1 and K2 columns, respectively. The restriction is B2 = 0. a. Using (5-23), prove that the restricted estimator is simply [b1*, 0], where b1* is the least squares coeffici
> Using the results in Exercise 1, test the hypothesis that the slope on x1 is 0 by running the restricted regression and comparing the two sums of squared deviations.
> The Grunfeld investment data in Appendix Table 10.4 constitute a classic data set that has been used for decades to develop and demonstrate estimators for seemingly unrelated regressions.28 Although somewhat dated at this juncture, they remain an ideal a
> Show that the model of the alternative hypothesis in Example 5.7 can be written As such, it does appear that H0 is a restriction on H1. However, because there are an infinite number of constraints, this does not reduce the test to a standard test of rest
> The log likelihood function for the linear regression model with normally distributed disturbances is shown in (14-39) in section 14.9.1. show that at the maximum likelihood estimators of b for B and e'e/n for s2, the log likelihood is an increasing func
> Suppose the true regression model is given by (4-7). The result in (4-9) shows that if pX.z is nonzero and g is nonzero, then regression of y on X alone produces a biased and inconsistent estimator of B. suppose the objective is to forecast y, not to est
> Show that in the multiple regression of y on a constant, x1 and x2 while imposing the restriction b1 + b2 = 1 leads to the regression of y - x1 on a constant and x2 - x1.
> A multiple regression of y on a constant x1 and x2 produces the following results: yn = 4 + 0.4x1 + 0.9x2, R2 = 8/60, e'e = 520, n = 29, Test the hypothesis that the two slopes sum to 1.
> For the classical normal regression model y = Xβ +( with no constant term and K regressors, assuming that the true value of b is zero, what is the exact expected value of F[K, n - K] = (R2/K)/[(1 - R2)/(n - K)]?
> Consider the multiple regression of y on K variables X and an additional variable z. Prove that under the assumptions A1 through A6 of the classical regression model, the true variance of the least squares estimator of the slopes on X is larger when z is
> The following sample moments for x = [1, x1, x2, x3] were computed from 100 observations produced using a random number generator: The true model underlying these data is y = x1 + x2 + x3 + e. a. Compute the simple correlations among the regressors. b. C
> As a profit-maximizing monopolist, you face the demand curve Q =  + P + . In the past, you have set the following prices and sold the accompanying quantities: Suppose that your marginal cost is 10. Ba
> Prove that the least squares intercept estimator in the classical regression model is the minimum variance linear unbiased estimator.
> Continuing the analysis of Section 10.3.2, we find that a translog cost function for one output and three factor inputs that does not impose constant returns to scale is The factor share equations are [See Christensen and Greene (1976) for analysis of th
> Suppose that the regression model is yi = + xi + i, where the disturbances i have f(i) = (1/) exp (-i/), i / . This model is rather peculiar in that all the disturbances are assumed to be nonnegative. Note that the disturbances have E[i/xi]
> Suppose that the classical regression model applies but that the true value of the constant is zero. Compare the variance of the least squares slope estimator computed without a constant term with that of the estimator computed with an unnecessary consta
> Consider the simple regression yi = xi + i where E[/x] = 0 and E[2 / x] = 2 a. What is the minimum mean squared error linear estimator of ? [Hint: Le
> For the simple regression model yi = + i, i ( N[0, 2], prove that the sample mean is consistent and asymptotically normally distributed. Now consider the alternative estimator mn = w y , w = i = i . Note that // Prove that this is a c
> Let ei be the ith residual in the ordinary least squares regression of y on X in the classical regression model, and let ei be the corresponding true disturbance. Prove that plim(ei - ei) = 0.
> For the classical normal regression model y = Xβ + ( with no constant term and K regressors, what is plim /assuming that the true value of β is zero?
> Prove that / where b is the ordinary least squares estimator and k is a characteristic root of X′X.
> Suppose that you have two independent unbiased estimators of the same parameter /with different variances v1 and v2. What linear combination / is the minimum variance unbiased estimator of /
> Example 4.10 presents a regression model that is used to predict the auction prices of Monet paintings. The most expensive painting in the sample sold for $33.0135M (ln = 17.3124). The height and width of this painting were 35″ and 39.4″, respectively. U
> In Section 4.9.2, we consider regressing y on a set of principal components, rather than the original data. For simplicity, assume that X does not contain a constant term, and that the K variables are measured in deviations from the means and are standar
> Statewide aggregate production function. Continuing Example 10.1, data on output, the capital stocks, and employment are aggregated by summing the values for the individual states (before taking logarithms). The unemployment rate for each region, m, at t
> In (4-13), we find that when superfluous variables X2 are added to the regression of y on X1 the least squares coefficient estimator is an unbiased estimator of the true parameter vector, β = (β′1, 0′)′. Show that, in this long regression, e′e/(n - K1 -
> Consider a data set consisting of n observations, nc complete and nm incomplete, for which the dependent variable, yi, is missing. Data on the independent variables, xi, are complete for all n observations, Xc and Xm. We wish to use the data to estimate
> Is it possible to partition R2? The idea of “hierarchical partitioning” is to decompose R2 into the contributions made by each variable in the multiple regression. That is, if x1, , xK are entered into a regression one at a time, then ck is the increment
> In the December 1969 American Economic Review (pp. 886–896), Nathaniel Leff reports the following least squares regression results for a cross section study of the effect of age composition on savings in 74 countries in 1964: ln S/Y = 7.3439 + 0.1596 ln
> Using the matrices of sums of squares and cross products immediately preceding section 3.2.3, compute the coefficients in the multiple regression of real investment on a constant, GNP, and the interest rate. Compute R2.
> Three variables, N, D, and Y, all have zero means and unit variances. A fourth variable is C = N + D. In the regression of C on Y, the slope is 0.8. In the regression of C on N, the slope is 0.5. In the regression of D on Y, the slope is 0.4. What is the
> Regression without a constant. suppose that you estimate a multiple regression first with, then without, a constant. Whether the R2 is higher in the second case than the first will depend in part on how it is computed. using the (relatively) standard met
> Change in adjusted R2. Prove that the adjusted R2 in (3-30) rises (falls) when variable xk is deleted from the regression if the square of the t ratio on xk in the multiple regression is less (greater) than 1.
> Demand system estimation. Let Y denote total expenditure on consumer durables, nondurables, and services and Ed, En, and Es are the expenditures on the three categories. As defined, Y = Ed + En + Es. Now, consider the expenditure system Ed = ad + bdY + g
> Deleting an observation. A common strategy for handling a case in which an observation is missing data for one or more variables is to fill those missing variables with 0s and add a variable to the model that takes the value 1 for that one observation an
> (We look ahead to our use of maximum likelihood to estimate the models discussed in this chapter in chapter 14.) In Example 9.3, we computed an iterated FGLS estimator using the airline data and the model The weights computed at each iteration were comp
> Adding an observation. A data set consists of n observations contained in Xn and yn. The least squares estimator based on these n observations is bn = (X= X )-1X= y . Another observation, xs and ys, becomes available. Prove that the least squares estimat
> Residual makers. What is the result of the matrix product M1M where M1 is defined in (3-19) and M is defined in (3-14)?
> Find the first two autocorrelations and partial autocorrelations for the MA(2) process
> It is commonly asserted that the Durbin–Watson statistic is only appropriate for testing for first-order autoregressive disturbances. The Durbin–Watson statistic estimates 2(1 - ) where r is the first-order autocorrelation of the residuals. What combina
> Derive the disturbance covariance matrix for the model What parameter is estimated by the regression of the OLS residuals on their lagged values?
> Prove that the Hessian for the tobit model in (19-14) is negative definite after Olsen’s transformation is applied to the parameters.
> Derive the partial effects for the tobit model with heteroscedasticity that is described in section 19.3.5.b.
> Continuing to use the data in Exercise 1, consider once again only the nonzero observations. Suppose that the sampling mechanism is as follows: y* and another normally distributed random variable z have population correlation 0.7. The two variables, y* a
> Using only the no limit observations, repeat Exercise 2 in the context of the truncated regression model. Estimate / by using the method of moments estimator outlined in Example 19.2. Compare your results with those in the previous exercises.
> This application is based on the following data set. a. compute the OLS regression of y on a constant, x1, and x2. Be sure to compute the conventional estimator of the asymptotic covariance matrix of the OLS estimator as well. b. compute the White esti
> We now consider the tobit model that applies to the full data set. a. Formulate the log likelihood for this very simple tobit model. b. Reformulate the log likelihood in terms of Then derive the necessary conditions for maximizing the log likelihood with
> The following 20 observations are drawn from a censored normal distribution: The applicable model is Exercises 1 through 4 in this section are based on the preceding information. The OLs estimator of  in the context of this tobit mo
> Consider estimation of a Poisson regression model for yi | xi. The data are truncated on the left—these are on-site observations at a recreation site, so zeros do not appear in the data set. The data are censored on the right—any response greater than 5
> For the zero-inflated Poisson (ZIP) model in section 18.4.8, we derived the conditional mean function, / a. For the same model, now obtain / Then, obtain Does the zero inflation produce overdispersion? (That is, is the ratio greater than one?) b. obtai
> We are interested in the ordered probit model. our data consist of 250 observations, of which the responses are using the preceding data, obtain maximum likelihood estimates of the unknown parameters of the model. (Hint: Consider the probabilities as t
> In the panel data models estimated in section 17.7, neither the logit nor the probit model provides a framework for applying a Hausman test to determine whether fixed or random effects is preferred. Explain. (Hint: Unlike our application in the linear mo
> Prove (17-26).
> A data set consists of n = n1 + n2 + n3 observations on y and x. For the first n1 observations, y = 1 and x = 1. For the next n2 observations, y = 0 and x = 1. For the last n3 observations, y = 0 and x = 0. Prove that neither (17-18) nor (17-20) has a so
> The following hypothetical data give the participation rates in a particular type of recycling program and the number of trucks purchased for collection by 10 towns in a small mid-Atlantic state: The town of Eleven is contemplating initiating a recycli
> Construct the Lagrange multiplier statistic for testing the hypothesis that all the slopes (but not the constant term) equal zero in the binomial logit model. Prove that the Lagrange multiplier statistic is nR2 in the regression of (yi - p) on the xs, wh
> In Example 8.5, we have suggested a model of a labor market. From the “reduced form” equation given first, you can see the full set of variables that appears in the model—that is the “endogenous variables,” ln Wageit, and Wksit, and all other exogenous v
> Given the data set estimate a probit model and test the hypothesis that x is not influential in determining the probability that y equals one.
> Suppose that a linear probability model is to be fit to a set of observations on a dependent variable y that takes values zero and one, and a single regressor x that varies continuously across observations. Obtain the exact expressions for the least squa
> A binomial probability model is to be based on the following index function model: The only regressor, d, is a dummy variable. The data consist of 100 observations that have the following: Obtain the maximum likelihood estimators of and b, and estimate
> Suppose the distribution of yi |  is Poisson, We will obtain a sample of observations, yi, , yn. suppose our prior for ï¬ï€ is the inverted gamma, which will imply a. construct the likelihood function,
> Derive the first-order conditions for nonlinear least squares estimation of the parameters in (15-2). How would you estimate the asymptotic covariance matrix for your estimator of /
> The Weibull population has survival function How would you obtain a random sample of observations from a Weibull population? (The survival function equals one minus the cdf.)
> The exponential distribution has density / How would you obtain a random sample of observations from an exponential population?
> Consider sampling from a multivariate normal distribution with mean vector and covariance matrix 2I. The log-likelihood function is show that the maximum likelihood estimators of the parameters are / and Derive the second derivativ
> For random sampling from the classical regression model in (14-3), reparameterize the likelihood function in terms of / Find the maximum likelihood estimators of and δ and obtain the asymptotic covariance matrix of the estimators of these parameters.
> Show that the likelihood inequality in Theorem 14.3 holds for the Poisson distribution used in section 14.3 by showing that / is uniquely maximized at θ = θθ. (Hint: First show that the expectation is / show that the likelihood inequality in Theorem 14
> Using the gasoline market data in Appendix Table F2.2, use the partially linear regression method in Section 7.4 to fit an equation of the form
> Limited Information Maximum Likelihood Estimation. Consider a bivariate distribution for x and y that is a function of two parameters, and b. The joint density is f(x, y | , ). We consider maximum likelihood estimation of the two parameters. The full i
> The following data were generated by the Weibull distribution of Exercise 4: a. Obtain the maximum likelihood estimates of a and , and estimate the asymptotic covariance matrix for the estimates. b. Carry out a Wald test of the hypoth
> Suppose that x has the Weibull distribution a. Obtain the log-likelihood function for a random sample of n observations. b. Obtain the likelihood equations for maximum likelihood estimation of and . Note that the first provides an expli
> Mixture distribution. suppose that the joint distribution of the two random variables x and y is a. Find the maximum likelihood estimators of  and θ and their asymptotic joint distribution. b. Find the maximum likelihood
> In random sampling from the exponential distribution // find the maximum likelihood estimator of θ and obtain the asymptotic distribution of this estimator.
> Assume that the distribution of x is In random sampling from this distribution, prove that the sample maximum is a consistent estimator of θ. Note: You can prove that the maximum is the maximum likelihood estimator of θ. But the
> Consider GMM estimation of a regression model as shown at the beginning of Example 13.8. Let W1 be the optimal weighting matrix based on the moment equations. Let W2 be some other positive definite matrix. Compare the asymptotic covariance matrices of th
> Consider the probit model analyzed in Chapter 17. The model states that for given vector of independent variables, Consider a GMM estimator based on the result that This suggests that we might base estimation on the orthogonality conditions Construct a G
> In the classical regression model with heteroscedasticity, which is more efficient, ordinary least squares or GMM? Obtain the two estimators and their respective asymptotic covariance matrices, then prove your assertion.
> For the Wald distribution discussed in Example 13.3, we have the following results / a. Derive the maximum likelihood estimators of  and  and an estimator of the asymptotic variances of the MLEs. (Hint: Expand the qua
> In Example 7.1, the cES function is suggested as a model for production, / (7-36) Example 6.19 suggested an indirect method of estimating the parameters of this model. The function is linearized around = 0, which produces an intrinsically linear approx
> The data listed in Table 3.5 are extracted from Koop and Tobias’s (2004) study of the relationship between wages and education, ability, and family characteristics. (see Appendix Table F3.2.) Their data set is a panel of 2,178 individua
> Using the bond from Practice Exercise 14-5A, journalize the first interest payment and the amortization of the related bond premium. Round to the nearest dollar. Data from Practice Exercise 14-5A: On the first day of the fiscal year, a company issues an
> On the first day of the fiscal year, a company issues a $5,300,000, 8%, five-year bond that pays semiannual interest of $212,000 ($5,300,000 × 8% × ½), receiving cash of $5,520,390. Journalize the bond issuance.
> Desmond Co. is considering the following alternative financing plans: Income tax is estimated at 40% of income. Determine the earnings per share of common stock, assuming that income before bond interest and income tax is $400,000.
> On January 31, Outback Coast Resorts Inc. reacquired 18,700 shares of its common stock at $45 per share. On April 20, Outback Coast Resorts sold 10,600 of the reacquired shares at $52 per share. On October 4, Outback Coast Resorts sold the remaining shar
> Red Market Corporation has 370,000 shares of $27 par common stock outstanding. On June 8, Red Market Corporation declared a 5% stock dividend to be issued August 12 to stockholders of record on July 13. The market price of the stock was $51 per share on
> Top-Value Corporation has 900,000 shares of $26 par common stock outstanding. On September 2, Top-Value Corporation declared a 3% stock dividend to be issued November 30 to stockholders of record on October 3. The market price of the stock was $44 per sh
> The declaration, record, and payment dates in connection with a cash dividend of $195,000 on a corporation’s common stock are February 1, March 18, and May 1. Journalize the entries required on each date.
> The declaration, record, and payment dates in connection with a cash dividend of $428,000 on a corporation’s common stock are February 28, April 1, and May 15. Journalize the entries required on each date.
> On January 22, Micah Corporation issued for cash 125,000 shares of no-par common stock at $6. On February 14, Micah Corporation issued at par value 32,000 shares of preferred 2% stock, $80 par for cash. On August 30, Micah Corporation issued for cash 7,0
> On May 23, Washburn Realty Inc. issued for cash 45,000 shares of no-par common stock (with a stated value of $4) at $16. On July 6, Washburn Realty Inc. issued at par value 12,000 shares of preferred 1% stock, $75 par for cash. On September 15, Washburn
> In teams, select a public company that interests you. Obtain the company’s most recent annual report on Form 10-K. The Form 10-K is a company’s annually required filing with the Securities and Exchange Commission (SEC). It includes the company’s financia
> Castillo Nutrition Company has 14,000 shares of cumulative preferred 1% stock, $130 par, and 70,000 shares of $5 par common stock. The following amounts were distributed as dividends: Year 1 ……………….. $35,000 Year 2 …………………… 6,300 Year 3 ………………… 80,500 De

