Question: In equation (7.29), suppose that we
In equation (7.29), suppose that we define outlf to be one if the woman is out of the
labor force, and zero otherwise.
(i) If we regress outlf on all of the independent variables in equation (7.29), what will happen to the
intercept and slope estimates? (Hint: inlf = 1 - outlf . Plug this into the population equation
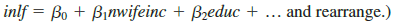
(ii) What will happen to the standard errors on the intercept and slope estimates?
(iii) What will happen to the R-squared?
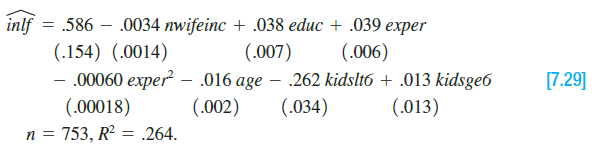
Transcribed Image Text:
inlf = Bo + Binwifeinc + Breduc + ... and rearrange.) inlf .586 – .0034 nwifeinc + .038 educ + .039 exper (.154) (.0014) .00060 exper – .016 age – (.00018) (.007) (.006) .262 kidsltá + .013 kidsge6 [7.29] (.002) (.034) (.013) n = 753, R2 = .264.
> In October 1979, the Federal Reserve changed its policy of using finely tuned interest rate adjustments and instead began targeting the money supply. Using the data in INTDEF, define a dummy variable equal to 1 for years after 1979. Include this dummy in
> One way to alleviate the multicollinearity problem is to assume that the δj follow a relatively simple pattern. For concreteness, consider a model with four lags: Now, let us assume that the dj follow a quadratic in the lag, j: for paramete
> Suppose you have quarterly data on new housing starts, interest rates, and real per capita income. Specify a model for housing starts that accounts for possible trends and seasonality in the variables.
> When the three event indicators befile6, affile6, and afdec6 are dropped from equation (10.22), we obtain R2 = .281 and R2 = .264. Are the event indicators jointly significant at the 10% level? log(chnimp) = -17.80 + 3.12 log(chempi) + .196 log(gas)
> Suppose yt follows a second order FDL model: Let z* denote the equilibrium value of zt and let y* be the equilibrium value of yt, such that Show that the change in y*, due to a change in z*, equals the long-run propensity times the change in z*: This giv
> Let gGDPt denote the annual percentage change in gross domestic product and let intt denote a short term interest rate. Suppose that gGDPt is related to interest rates by where ut is uncorrelated with intt, intt-1, and all other past values of interest
> Decide if you agree or disagree with each of the following statements and give a brief explanation of your decision: (i) Like cross-sectional observations, we can assume that most time series observations are Independently distributed. (ii) The OLS estim
> In the linear model given in equation (10.8), the explanatory variables xt = (xt1,…., xtk ) are said to be sequentially exogenous (sometimes called weakly exogenous) if so that the errors are unpredictable given current and all past v
> Use the data in APPROVAL to answer the following questions. The data set consists of 78 months of data during the presidency of George W. Bush. (The data end in July 2007, before Bush left office.) In addition to economic variables and binary indicators
> Use the data in MINWAGE for this exercise. In particular, use the employment and wage series for sector 232 (Men’s and Boys’ Furnishings). The variable gwage232 is the monthly growth (change in logs) in the average wage in sector 232, gemp232 is the grow
> (i) Estimate equation (10.2) using all the data in PHILLIPS and report the results in the usual form. How many observations do you have now? (ii) Compare the estimates from part (i) with those in equation (10.14). In particular, does adding the extra yea
> The file TRAFFIC2 contains 108 monthly observations on automobile accidents, traffic laws, and some other variables for California from January 1981 through December 1989. Use this data set to answer the following questions. (i) During what month and yea
> Consider the model estimated in (10.15); use the data in INTDEF. (i) Find the correlation between inf and def over this sample period and comment. (ii) Add a single lag of inf and def to the equation and report the results in the usual form. (iii) Compar
> Use the data in VOLAT for this exercise. The variable rsp500 is the monthly return on the Standard & Poor’s 500 stock market index, at an annual rate. (This includes price changes as well as dividends.) The variable i3 is the return
> Use the data in FERTIL3 for this exercise. (i) Add pet23 and pet24 to equation (10.19). Test for joint significance of these lags. (ii) Find the estimated long-run propensity and its standard error in the model from part (i). Compare these with those obt
> Use the data set CONSUMP for this exercise. (i) Estimate a simple regression model relating the growth in real per capita consumption (of nondurables and services) to the growth in real per capita disposable income. Use the change in the logarithms in bo
> Use the data in FERTIL3 for this exercise. (i) Regress gfrt on t and t2 and save the residuals. This gives a detrended gfrt, say, g
> Use the data in EZANDERS for this exercise. The data are on monthly unemployment claims in Anderson Township in Indiana, from January 1980 through November 1988. In 1984, an enterprise zone (EZ) was located in Anderson (as well as other cities in Indiana
> Use the data in FERTIL3 to verify that the standard error for the LRP in equation (10.19) is about .030. = 95.87 + .073 pe, gfr, (3.28) (.126) 70, R? = .499, R² – .0058 pe,-1 + .034 pe,-2 (.1557) 22.12 ww2, – 31.30 pill, - (.126) (10.73) (3.98) [10.1
> Add the variable log( prgnp) to the minimum wage equation in (10.38). Is this variable significant? Interpret the coefficient. How does adding log( prgnp) affect the estimated minimum wage effect?
> Use the data in BARIUM for this exercise. (i) Add a linear time trend to equation (10.22). Are any variables, other than the trend, statistically significant? (ii) In the equation estimated in part (i), test for joint significance of all variables except
> The model that explicitly contains the long-run propensity, θ0, as where we omit the other explanatory variables for simplicity. As always with multiple regression analysis, θ0 should have a ceteris paribus interpretation. Namel
> Use the data in HPRICE1 to obtain the heteroskedasticity-robust standard errors for equation (8.17). Discuss any important differences with the usual standard errors. (ii) Repeat part (i) for equation (8.18). (iii) What does this example suggest about he
> Consider the following model to explain sleeping behavior: (i) Write down a model that allows the variance of u to differ between men and women. The variance should not depend on other factors. (ii) Use the data in SLEEP75 to estimate the parameters of t
> If we start with (6.38) under the CLM assumptions, assume large n, and ignore the estimation error in the
> Suppose we want to estimate the effects of alcohol consumption (alcohol) on college grade point average (colGPA). In addition to collecting information on grade point averages and alcohol usage, we also obtain attendance information (say, percentage of
> The following three equations were estimated using the 1,534 observations in 401K: Which of these three models do you prefer? Why? 80.29 + 5.44 mrate + .269 age – .00013 totemp (.78) (.52) prate (.045) (.00004) R? = .100, R = .098. 97.32 + 5.02 mrat
> When atndrte2 and ACT # atndrte are added to the equation estimated in (6.19), the R-squared becomes .232. Are these additional terms jointly significant at the 10% level? Would you include them in the model? stndfnl = 2.05 - .0067 atndrte 1.63 pri
> In Example 4.2, where the percentage of students receiving a passing score on a tenth-grade math exam (math10) is the dependent variable, does it make sense to include sci11—the percentage of eleventh graders passing a science exam—as an ad
> The following model allows the return to education to depend upon the total amount of both parents’ education, called pareduc: Show that, in decimal form, the return to another year of education in this model is What sign do you expect
> Use the data in 401KSUBS for this question, restricting the sample to fsize 5 1. (i) To the model estimated in Table 8.1, add the interaction term, e401k · inc. Estimate the equation by OLS and obtain the usual and robust standard errors. W
> Using the data in RDCHEM, the following equation was obtained by OLS: (i) At what point does the marginal effect of sales on rdintens become negative? (ii) Would you keep the quadratic term in the model? Explain. (iii) Define salesbil as sales measured i
> Let
> The following two equations were estimated using the data in MEAPSINGLE. The key explanatory variable is lexppp, the log of expenditures per student at the school level. (i) If you are a policy maker trying to estimate the causal effect of per-student s
> The following equation was estimated using the data in CEOSAL1: This equation allows roe to have a diminishing effect on log(salary). Is this generality necessary? Explain why or why not. .00008 roe? log(salary) = 4.322 + .276 log(sales) + .0215 roe
> Let d be a dummy (binary) variable and let z be a quantitative variable. Consider the model this is a general version of a model with an interaction between a dummy variable and a quantitative variable. (i) Since it changes nothing important, set the err
> Suppose you collect data from a survey on wages, education, experience, and gender. In addition, you ask for information about marijuana usage. The original question is: “On how many separate occasions last month did you smoke marijuana?” (i) Write an e
> To test the effectiveness of a job training program on the subsequent wages of workers, we specify the model where train is a binary variable equal to unity if a worker participated in the program. Think of the error term u as containing unobserved worke
> Let noPC be a dummy variable equal to one if the student does not own a PC, and zero otherwise. (i) If noPC is used in place of PC in equation (7.6), what happens to the intercept in the estimated equation? What will be the coefficient on noPC? (Hint: Wr
> An equation explaining chief executive officer salary is The data used are in CEOSAL1, where finance, consprod, and utility are binary variables indicating the financial, consumer products, and utilities industries. The omitted industry is transportatio
> Use the data set 401KSUBS for this exercise. (i) Using OLS, estimate a linear probability model for e401k, using as explanatory variables inc, inc2, age, age2, and male. Obtain both the usual OLS standard errors and the heteroscedasticity-robust versions
> Using the data in GPA2, the following equation was estimated: The variable sat is the combined SAT score; hsize is size of the student’s high school graduating class, in hundreds; female is a gender dummy variable; and black is a race
> The following equations were estimated using the data in BWGHT: And The variables are defined as in Example 4.9, but we have added a dummy variable for whether the child is male and a dummy variable indicating whether the child is classified as white. (
> The following equations were estimated using the data in ECONMATH, with standard errors reported under coefficients. The average class score, measured as a percentage, is about 72.2; exactly 50% of the students are male; and the average of colgpa (grade
> For a child i living in a particular school district, let voucheri be a dummy variable equal to one if a child is selected to participate in a school voucher program, and let scorei be that child’s score on a subsequent standardized exam. Suppose that th
> The estimated equation The variable sleep is total minutes per week spent sleeping at night, totwrk is total weekly minutes spent working, educ and age are measured in years, and male is a gender dummy. (i) All other factors being equal, is there evidenc
> The following equations were estimated using the data in ECONMATH. The first equation is for men and the second is for women. The third and fourth equations combine men and women. (i) Compute the usual Chow statistic for testing the null hypothesis that
> Consider a model at the employee level, where the unobserved variable fi is a “firm effect” to each employee at a given firm i. The error term vi,e is specific to employee e at firm i. The composite error is ui,e = fi
> There are different ways to combine features of the Breusch-Pagan and White tests for heteroskedasticity. One possibility not covered in the text is to run the regression where the µ I are the OLS residuals and the on X;1, X2, ... Xik
> The variable smokes is a binary variable equal to one if a person smokes, and zero otherwise. Using the data in SMOKE, we estimate a linear probability model for smokes: The variable white equals one if the respondent is white, and zero otherwise. Both t
> Using the data in GPA3, the following equation was estimated for the fall and second semester students: Here, trmgpa is term GPA, crsgpa is a weighted average of overall GPA in courses taken, cumgpa is GPA prior to the current semester, tothrs is total
> (i) Obtain the OLS estimates in equation (8.35). (ii) Obtain the /used in the WLS estimation of equation (8.36) and reproduce equation (8.36). From this equation, obtain the unweighted residuals and fitted values; call these
> True or False: WLS is preferred to OLS when an important variable has been omitted from the model.
> Consider a linear model to explain monthly beer consumption: Write the transformed equation that has a homoskedastic error term. beer = Bo + Binc + Bzprice + B3zeduc + Bafemale + u E(ulinc, price, educ, female) = 0 Var(ulinc, price, educ, female) = o
> Which of the following are consequences of heteroskedasticity? (i) The OLS estimators, β j, are inconsistent. (ii) The usual F statistic no longer has an F distribution. (iii) The OLS estimators are no longer BLUE.
> This exercise shows that in a simple regression model, adding a dummy variable for missing data on the explanatory variable produces a consistent estimator of the slope coefficient if the “missingness” is unrelated to
> Suppose that log1y2 follows a linear model with a linear form of heteroskedasticity. We write this as so that, conditional on x, u has a normal distribution with mean (and median) zero but with variance h(x) that depends on x. Because Med(u|x) = 0, equat
> The point of this exercise is to show that tests for functional form cannot be relied on as a general test for omitted variables. Suppose that, conditional on the explanatory variables
> Consider the simple regression model with classical measurement error, y =
> In the model (9.17), show that OLS consistently estimates a and b if
> In Example 4.4, we estimated a model relating number of campus crimes to student enrollment for a sample of colleges. The sample we used was not a random sample of colleges in the United States, because many schools in 1992 did not report campus crimes.
> The following equation explains weekly hours of television viewing by a child in terms of the child’s age, mother’s education, father’s education, and number of siblings: We are worried that tvhoursp
> Use the data set GPA1 for this exercise. (i) Use OLS to estimate a model relating colGPA to hsGPA, ACT, skipped, and PC. Obtain the OLS residuals. (ii) Compute the special case of the White test for heteroskedasticity. In the regression of
> Let math10 denote the percentage of students at a Michigan high school receiving a passing score on a standardized math test (see also Example 4.2). We are interested in estimating the effect of per-student spending on math performance. A simple model is
> Let us modify Computer Exercise C4 in Chapter 8 by using voting outcomes in 1990 for incumbents who were elected in 1988. Candidate A was elected in 1988 and was seeking reelection in 1990; voteA90 is Candidate A’s share of the two-part
> The R-squared from estimating the model using the data in CEOSAL2, was R2 5=.353 (n = 177) . When ceoten2 and comten2 are added, R2 = .375. Is there evidence of functional form misspecification in this model? log(salary) = Bo + Bilog(sales) + Bzlog(m
> Use the data in ECONMATH to answer this question. The population model is (i) For how many students is the ACT score missing? What is the fraction of the sample? Define a new variable, actmiss, which equals one if act is missing, and zero otherwise. (ii)
> Use the data in CEOSAL2 to answer this question. (i) Estimate the model by OLS using all of the observations, where lsalary, lsales, and lmktvale are all natural logarithms. Report the results in the usual form with the usual OLS standard errors. (You ma
> (i) Using all of the data, run the regression lavgsal on bs, lenrol, lstaff, and lunch. Report the coefficient on bs along with its usual and heteroskedasticity-robust standard errors. What do you conclude about the economic and statistical significance
> Use the data in MURDER only for the year 1993 for this question, although you will need to first obtain the lagged murder rate, say mrdrte21. (i) Run the regression of mrdrte on exec, unem. What are the coefficient and t statistic on exec? Does this regr
> You need to use two data sets for this exercise, JTRAIN2 and JTRAIN3. The former is the outcome of a job training experiment. The file JTRAIN3 contains observational data, where individuals themselves largely determine whether they participate in job tra
> You are to compare OLS and LAD estimates of the effects of 401(k) plan eligibility on net financial assets. The model is (i) Use the data in 401KSUBS to estimate the equation by OLS and report the results in the usual form. Interpret the coefficient on e
> Use the data in TWOYEAR for this exercise. (i) The variable stotal is a standardized test variable, which can act as a proxy variable for unobserved ability. Find the sample mean and standard deviation of stotal. (ii) Run simple regressions of jc and uni
> Use the data in LOANAPP for this exercise. (i) Estimate the equation in part (iii) of Computer Exercise C8 in Chapter 7, computing the heteroskedasticity- robust standard errors. Compare the 95% confidence interval on Bwhite with the nonrobust confidence
> Use the data in LOANAPP for this exercise. (i) How many observations have obrat > 40, that is, other debt obligations more than 40% of total income? (ii) Reestimate the model in part (iii) of Computer Exercise C8, excluding observations with obrat > 40.
> In example given below by dropping schools where teacher benefits are less than 1% of salary. (i) How many observations are lost? (ii) Does dropping these observations have any important effects on the estimated tradeoff? Example: Let totcomp denote aver
> Use the data in RDCHEM to further examine the effects of outliers on OLS estimates and to see how LAD is less sensitive to outliers. The model is where you should first change sales to be in billions of dollars to make the estimates easier to interpret.
> Use the data for the year 1990 in INFMRT for this exercise. (i) Reestimate equation (9.43), but now include a dummy variable for the observation on the District of Columbia (called DC). Interpret the coefficient on DC and comment on its size and signific
> Use the data from JTRAIN for this exercise. (i) Consider the simple regression model where scrap is the firm scrap rate and grant is a dummy variable indicating whether a firm received a job training grant. Can you think of some reasons why the unobserve
> Use the data set WAGE2 for this exercise. (i) Use the variable KWW (the “knowledge of the world of work” test score) as a proxy for ability. What is the estimated return to education in this case? (ii) Now, use IQ and KWW together as proxy variables. Wha
> (i) Apply RESET from equation (9.3) to the model estimated.. Is there evidence of functional form misspecification in the equation? (ii) Compute a heteroskedasticity-robust form of RESET. Does your conclusion from part (i) change? y β + βχ + + Brik +
> The data set NBASAL contains salary information and career statistics for 269 players in the National Basketball Association (NBA). Estimate a model relating points-per-game (points) to years in the league (exper), age, and years played in college (coll)
> Use the data in HPRICE1 for this exercise. (i) Estimate the model and report the results in the usual form, including the standard error of the regression. Obtain predicted price, when we plug in lotsize 5 10,000, sqrft 5 2,300, and bdrms 5 4; round this
> Use the data in ATTEND for this exercise. In the model of Example 6.3, argue that Use equation (6.19) to estimate the partial effect when priGPA 5 2.59 and atndrte 5 82. Interpret your estimate. Show that the equation can be written as where Î&cedi
> (i) Using the data in CRIME1, estimate this model by OLS and verify that all fitted values are strictly between zero and one. What are the smallest and largest fitted values? (ii) Estimate the equation by weighted least squares, as discussed in Section 8
> Use the data in VOTE1 for this exercise. Consider a model with an interaction between expenditures: What is the partial effect of expendB on voteA, holding prtystrA and expendA fixed? What is the partial effect of expendA on voteA? Is the expected sign f
> Use the housing price data in HPRICE1 for this exercise. Estimate the model and report the results in the usual OLS format. (ii) Find the predicted value of log(price), when lotsize = 20,000, sqrft = 2,500, and bdrms = 4. Find the predicted value of pric
> Use the data in GPA2 for this exercise. Estimate the model where hsize is the size of the graduating class (in hundreds), and write the results in the usual form. Is the quadratic term statistically significant? (ii) Using the estimated equation from par
> Consider a model where the return to education depends upon the amount of work experience (and vice versa): (i) Show that the return to another year of education (in decimal form), holding exper fixed, is β1 + β3exper. (ii) State
> Use the data in WAGE1 for this exercise. Use OLS to estimate the equation and report the results using the usual format. Is exper2 statistically significant at the 1% level? Using the approximation find the approximate return to the fifth year of exper
> Use the data in BENEFITS to answer this question. It is a school-level data set at the K–5 level on average teacher salary and benefits. See Example 4.10 for background. (i) Regress lavgsal on bs and report the results in the usual form
> Use the data in MEAP00 to answer this question. (i) Estimate the model / by OLS, and report the results in the usual form. Is each explanatory variable statistically significant at the 5% level? (ii) Obtain the fitted values from the regression in part
> Use the subset of 401KSUBS with fsize 5 1; this restricts the analysis to single-person households; see also Computer Exercise C8 in Chapter 4. (i) What is the youngest age of people in this sample? How many people are at that age? (ii) In the model wha
> (i) Run the regression ecolbs on ecoprc, regprc and report the results in the usual form, including the R-squared and adjusted R-squared. Interpret the coefficients on the price variables and comment on their signs and magnitudes. (ii) Are the price va
> Use the data in BWGHT2 for this exercise. (i) Estimate the equation by OLS, and report the results in the usual way. Is the quadratic term significant? (ii) Show that, based on the equation from part (i), the number of prenatal visits that maximizes log(
> Use the data in PNTSPRD for this exercise. (i) The variable sprdcvr is a binary variable equal to one if the Las Vegas point spread for a college basketball game was covered. The expected value of sprdcvr, say m, is the probability that the spread is cov
> Use the data in KIELMC, only for the year 1981, to answer the following questions. The data are for houses that sold during 1981 in North Andover, Massachusetts; 1981 was the year construction began on a local garbage incinerator. (i) To study the effect
> There has been much interest in whether the presence of 401(k) pension plans, available to many U.S. workers, increases net savings. The data set 401KSUBS contains information on net financial assets (nettfa), family income (inc), a binary variable for
> Use the data in LOANAPP for this exercise. The binary variable to be explained is approve, which is equal to one if a mortgage loan to an individual was approved. The key explanatory variable is white, a dummy variable equal to one if the applicant was w
> Use the data in WAGE1 for this exercise. (i) Use equation (7.18) to estimate the gender differential when educ = 12.5. Compare this with the estimated differential when educ = 0. (ii) Run the regression used to obtain (7.18), but with female (educ - 12.5

