Question: Maximum-urgency-first (MUF) is a real-
Maximum-urgency-first (MUF) is a real-time scheduling algorithm for periodic tasks. Each task is assigned an urgency that is defined as a combination of two fixed priorities and one dynamic priority. One of the fixed priorities, the criticality, has precedence over the dynamic priority. Meanwhile, the dynamic priority has precedence over the other fixed priority, called the user priority. The dynamic priority is inversely proportional to the laxity of a task. MUF can be explained as follows. First, tasks are ordered from shortest to longest period. Define the critical task set as the first N tasks such that worst-case processor utilization does not exceed 100%. Among critical set tasks that are ready, the scheduler selects the task with the least laxity. If no critical set tasks are ready, the schedule chooses among the noncritical tasks the one with the least laxity. Ties are broken through an optional user priority then by FCFS. Repeat Problem 10.3d, adding MUF to the diagrams. Assume user-defined priorities are A highest, B next, C lowest. Comment on the results.
Data from Problem 10.3d:
d. Consider a set of three periodic tasks with the execution profiles of Table 10.9a. Develop scheduling diagrams similar to those of Figure 10.5 for this set of tasks that compare rate monotonic, earliest-deadline first, and LLF. Assume preemption may occur at 5-ms intervals. Comment on the results.
Table 10.9a:

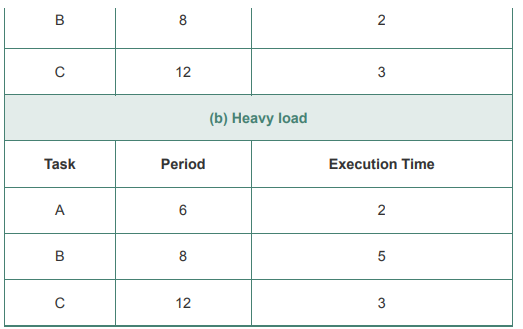
Figure 10.5:

Transcribed Image Text:
Table 10.9 Execution Profiles for Problems 10.3 through 10.6 (a) Light load Task Period Execution Time A 2 8 12 3 (b) Heavy load Task Period Execution Time A 6 2 5 12 2. 3. BI deadline B2 deadline AI deadline A2 deadline A3 deadline A4 deadline AS deadline Arrival times, execution times, and deadlines A2 A3 AS Al BI A4 B2 20 30 4 sp o 20 Time (ms) 10 90 Fixed-priority scheduling: AI BI A has priority A2 BI A3 B2 A4 B2 AS B2 i AI A2 BI A3 ASi B2 i (missed) B2 A5 Fixed-priority scheduling: B has priority IBI A2 A3 A3 A4 AS B2 (missed) (missed) Earliest-deadline scheduling Al using completion deadlines BI A2 Bli A3 B2 A4 AS AI A2 BI A3 A4 AS, B2 Figure 10.5 Scheduling of Periodic Real-Time Tasks with Completion Deadlines (Based on Table 10.3 D)
> Define the two types of distributed deadlock.
> List three general categories of information in a process control block.
> Define jacketing.
> List two disadvantages of ULTs compared to KLTs.
> List three advantages of ULTs over KLTs.
> What resources are typically shared by all of the threads of a process?
> Give four general examples of the use of threads in a single user multiprocessing system.
> What are the two separate and potentially independent characteristics embodied in the concept of process?
> List reasons why a mode switch between threads may be cheaper than a mode switch between processes.
> Table 3.5 lists typical elements found in a process control block for an unthreaded OS. Of these, which should belong to a thread control block, and which should belong to a process control block for a multithreaded system? Table 3.5: Process Identi
> For what types of entities does the OS maintain tables of information for management purposes?
> What is the difference between distributed mutual exclusion enforced by a centralized algorithm and enforced by a distributed algorithm?
> List four characteristics of a suspended process.
> Why does Figure 3.9b have two blocked states? Figure 3.9b: New Suspend Activate Dispatch Release Ready/ Suspend Ready Running Exit Suspend Time-out Activate Blocked/ Suspend Blocked Suspend (b) With two Suspend states Event upy occurs Admit Event oc
> What is swapping and what is its purpose?
> What does it mean to preempt a process?
> For the processing model of Figure 3.6, briefly define each state. Figure 3.6: Dispatch Admit Release New Ready Running Exit Time-out Event Event occurs wait Blocked
> What common events lead to the creation of a process?
> Generalize Equations (1.1) and (1.2) in Appendix 1A to n-level memory hierarchies.
> Directories can be implemented either as “special files” that can only be accessed in limited ways or as ordinary data files. What are the advantages and disadvantages of each approach?
> What are the advantages of using directories?
> Ignoring overhead for directories and file descriptors, consider a file system in which files are stored in blocks of 16K bytes. For each of the following file sizes, calculate the percentage of wasted file space due to incomplete filling of the last blo
> Both the search and the insertion time for a B-tree are a function of the height of the tree. We would like to develop a measure of the worst-case search or insertion time. Consider a B-tree of degree d that contains a total of n keys. Develop an inequal
> An alternative algorithm for insertion into a B-tree is the following: As the insertion algorithm travels down the tree, each full node that is encountered is immediately split, even though it may turn out that the split was unnecessary. a. What is the a
> For the B-tree in Figure 12.4c, show the result of inserting the key 97. Figure 12.4: Key, Key, Key- Subtree; Subtree, Subtree Subtree, Subree, Figure 12.4 A B-tree Node with k Children
> What file organization would you choose to maximize efficiency in terms of speed of access, use of storage space, and ease of updating (adding/deleting/modifying) when the data are: a. updated infrequently and accessed frequently in random order? b. upda
> What is an instruction trace?
> One scheme to avoid the problem of preallocation versus waste or lack of contiguity is to allocate portions of increasing size as the file grows. For example, begin with a portion size of one block, and double the portion size for each allocation. Consid
> Some operating systems have a tree–structured file system but limit the depth of the tree to some small number of levels. What effect does this limit have on users? How does this simplify file system design (if it does)?
> Define: B=block size R=record size P=size of block pointer F=blocking factor; expected number of records within a block Give a formula for F for the three blocking methods depicted in Figure 12.8 Figure 12.8: Record I Record 2 Record 3 Record 4 Trac
> Repeat the preceding problem using DMA, and assume one interrupt per sector. Data from problem 11.8: There are 512 bytes/sector. Since each byte generates an interrupt, there are 512 interrupts. Total interrupt processing time = 2.5 × 512 = 1280 µs. The
> Consider the disk system described in Problem 11.7, and assume the disk rotates at 360 rpm. A processor reads one sector from the disk using interrupt-driven I/O, with one interrupt per byte. If it takes to process each interrupt, what percentage of the
> Calculate how much disk space (in sectors, tracks, and surfaces) will be required to store 300,000 120-byte logical records if the disk is fixed sector with 512 bytes/sector, with 96 sectors/track, 110 tracks per surface, and 8 usable surfaces. Ignore an
> For the frequency-based replacement algorithm (see Figure 11.9), define Fnew, Fmiddle and Fold as the fraction of the cache that comprises the new, middle, and old sections, respectively. Clearly, Fnew+Fmiddle+Fold=1. Characterize the policy when a. Fold
> The following equation was suggested both for cache memory and disk cache memory: TS=TC+M×TD Generalize this equation to a memory hierarchy with N levels instead of just 2
> Consider a disk with N tracks numbered from 0 to (N-1) and assume requested sectors are distributed randomly and evenly over the disk. We want to calculate the average number of tracks traversed by a seek. a. Calculate the probability of a seek of length
> a. Perform the same type of analysis as that of Table 11.2 for the following sequence of disk track requests: 27, 129, 110, 186, 147, 41, 10, 64, 120. Assume the disk head is initially positioned over track 100 and is moving in the direction of decreasin
> In general terms, what are the four distinct actions that a machine instruction can specify?
> Generalize the result of Problem 11.1 to the case in which a program refers to n devices. Result of Problem 11.1: If the calculation time exactly equals the I/O time (which is the most favorable situation), both the processor and the peripheral device r
> An interactive system using round-robin scheduling and swapping tries to give guaranteed response to trivial requests as follows. After completing a round-robin cycle among all ready processes, the system determines the time slice to allocate to each rea
> Consider a 4-drive, 200 GB-per-drive RAID array. What is the available data storage capacity for each of the RAID levels, 0, 1, 3, 4, 5, and 6?
> It should be clear that disk striping can improve the data transfer rate when the strip size is small compared to the I/O request size. It should also be clear that RAID 0 provides improved performance relative to a single large disk, because multiple I/
> A 32-bit computer has two selector channels and one multiplexor channel. Each selector channel supports two magnetic disk and two magnetic tape units. The multiplexor channel has two line printers, two card readers, and ten VDT terminals connected to it.
> Consider a program that accesses a single I/O device and compare unbuffered I/O to the use of a buffer. Show that the use of the buffer can reduce the running time by at most a factor of two.
> Define residence time Tr as the average total time a process spends waiting and being served. Show that for FIFO, with mean service time Ts, we have Tr=Ts/(1−ρ), where is utilization.
> Draw a diagram similar to that of Figure 10.9b that shows the sequence events for this same example using priority ceiling. Figure 10.9b: Blocked by T, (attempt to lock s) s locked T2 Preempted by T Preempted by T; s unlocked s locked T3 14 I5 Time
> This problem demonstrates that although Equation (10.2) for rate monotonic scheduling is a sufficient condition for successful scheduling, it is not a necessary condition (i.e., sometimes successful scheduling is possible even if Equation (10.2) is not s
> Repeat Problem 10.4, adding MUF to the diagrams. Comment on the results. Data from Problem10.4: d. Consider a set of three periodic tasks with the execution profiles of Table 10.9a. Develop scheduling diagrams similar to those of Figure 10.5 for this set
> Define the two main categories of processor registers.
> Repeat Problem 10.3d for the execution profiles of Table 10.9b. Comment on the results. Data from Problem 10.3d: d. Consider a set of three periodic tasks with the execution profiles of Table 10.9a. Develop scheduling diagrams similar to those of Figure
> Least-laxity-first (LLF) is a real-time scheduling algorithm for periodic tasks. Slack time, or laxity, is the amount of time between when a task would complete if it started now and its next deadline. This is the size of the available scheduling window.
> Consider a set of five aperiodic tasks with the execution profiles of Table 10.8. Develop scheduling diagrams similar to those of Figure 10.6 for this set of tasks. Table 10.8: Figure 10.6: Table 10.8 Execution Profile for Problem 10.2 Process Arriv
> In a queuing system, new jobs must wait for a while before being served. While a job waits, its priority increases linearly with time from zero at a rate A job waits until its priority reaches the priority of the jobs in service; then, it begins to share
> Consider a variant of the RR scheduling algorithm where the entries in the ready queue are pointers to the PCBs. a. What would be the effect of putting two pointers to the same process in the ready queue? b. What would be the major advantage of this sche
> A processor is multiplexed at infinite speed among all processes present in a ready queue with no overhead. (This is an idealized model of round-robin scheduling among ready processes using time slices that are very small compared to the mean service tim
> Consider a set of three periodic tasks with the execution profiles of Table 10.7. Develop scheduling diagrams similar to those of Figure 10.5 for this set of tasks. Table 10.7: Figure 10.5: Table 10.7 Execution Profile for Problem 10.1 Process Arriv
> Prove that the minimax response ratio algorithm of the preceding problem minimizes the maximum response ratio for a given batch of jobs. (Hint: Focus attention on the job that will achieve the highest response ratio and all jobs executed before it. t1,
> In a nonpreemptive uniprocessor system, the ready queue contains three jobs at time t immediately after the completion of a job. These jobs arrived at times t1, t2, and t3 with estimated execution times of and respectively. Figure 9.18 shows the linear i
> List and briefly define the four main elements of a computer.
> Why is it impossible to determine a true global state?
> In the bottom example in Figure 9.5 , process A runs for two time units before control is passed to process B. Another plausible scenario would be that A runs for three time units before control is passed to process B. What policy differences in the feed
> Consider the following pair of equations as an alternative to Equation 9.3: Sn+1=αTn+(1−α)SnXn+1= min [Ubound, max[Lbound, (βSn+1)]] where Ubound and Lbound are prechosen upper and lower bounds on the estimated value of T. The value Xn+1 of is used in th
> Assume the following burst-time pattern for a process: 6, 4, 6, 4, 13, 13, 13, and assume the initial guess is 10. Produce a plot similar to those of Figure 9.9. Figure 9.9: 10 a= 0.8 a= 0.5 Simple average Observed value 2 3 45 9 10 11 12 13 14 15 1
> Prove that, among nonpreemptive scheduling algorithms, SPN provides the minimum average waiting time for a batch of jobs that arrive at the same time. Assume the scheduler must always execute a task if one is available.
> Consider the following set of processes: Perform the same analysis as depicted in Table 9.5 and Figure 9.5 for this set. Table 9.5: Figure 9.5: Process Arrival Time Processing Time A 3 В 1 3 D E 12 5 2. Table 9.5 A Comparison of Scheduling Policies
> Consider the following workload: a. Show the schedule using shortest remaining time, non preemptive priority (a smaller priority number implies higher priority) and round robin with quantum 30 ms. Use time scale diagram as shown below for the FCFS examp
> The IBM System/370 architecture uses a two-level memory structure and refers to the two levels as segments and pages, although the segmentation approach lacks many of the features described earlier in this chapter. For the basic 370 architecture, the pag
> Suppose the program statement is executed in a memory with page size of 1,000 words. Let n=1,000.Using a machine that has a full range of register-to-register instructions and employs index registers, write a hypothetical program to implement the forego
> In the VAX, user page tables are located at virtual addresses in the system space. What is the advantage of having user page tables in virtual rather than main memory? What is the disadvantage?
> A process contains eight virtual pages on disk and is assigned a fixed allocation of four page frames in main memory. The following page trace occurs: 1, 0, 2, 2, 1, 7, 6, 7, 0, 1, 2, 0, 3, 0, 4, 5, 1, 5, 2, 4, 5, 6, 7, 6, 7, 2, 4, a. Show the successive
> List the key design issues for an SMP operating system.
> A process references five pages, A, B, C, D, and E, in the following order: A; B; C; D; A; B; E; A; B; C; D; E Assume the replacement algorithm is first-in-first-out and find the number of page transfers during this sequence of references starting with a
> Consider the following string of page references 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2. C[ i, j ]=A[ i, j ]+B[ i, j ] Complete a figure similar to Figure 8.14, showing the frame allocation for: a. FIFO (first-in-first-out) b. LRU (least recently used) c.
> a. How much memory space is needed for the user page table of Figure 8.3 ? b. Assume you want to implement a hashed inverted page table for the same addressing scheme as depicted in Figure 8.3 , using a hash function that maps the 20-bit page number into
> Consider the following program. Assume the program is running on a system using demand paging, and the page size is 1 kB. Each integer is 4 bytes long. It is clear that each array requires a 16-page space. As an example, A[0, 0]-A[0, 63], A[1, 0]-A[1, 6
> A key to the performance of the VSWS resident set management policy is the value of Q. Experience has shown that with a fixed value of Q for a process, there are considerable differences in page fault frequencies at various stages of execution. Furthermo
> Consider the following sequence of page references (each element in the sequence represents a page number): 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 Define the mean working set size after the kth reference as sk(Δ)=1k ∑t=1k|W
> In the S/370 architecture, a storage key is a control field associated with each page-sized frame of real memory. Two bits of that key that are relevant for page replacement are the reference bit and the change bit. The reference bit is set to 1 when any
> In discussing a page replacement algorithm, one author makes an analogy with a snowplow moving around a circular track. Snow is falling uniformly on the track, and a lone snowplow continually circles the track at constant speed. The snow that is plowed o
> Consider a page reference string for a process with a working set of M frames, initially all empty. The page reference string is of length P with N distinct page numbers in it. For any page replacement algorithm, a. What is a lower bound on the number of
> Consider a system with memory mapping done on a page basis and using a single-level page table. Assume the necessary page table is always in memory. a. If a memory reference takes 200 ns, how long does a paged memory reference take? b. Now we add an MM
> What is multithreading?
> Assuming a page size of 4 kB and that a page table entry takes 4 bytes, how many levels of page tables would be required to map a 64-bit address space, if the top-level page table fits into a single page?
> Suppose the page table for the process currently executing on the processor looks like the following. All numbers are decimal, everything is numbered starting from zero, and all addresses are memory byte addresses. The page size is 1,024 bytes. a. Descr
> Let buddyk(x) = address of the buddy of the block of size 2k whose address is x. Write a general expression for buddyk(x).
> Consider a buddy system in which a particular block under the current allocation has an address of 011011110000. a. If the block is of size 4, what is the binary address of its buddy? b. If the block is of size 16, what is the binary address of its buddy
> A 1-Mbyte block of memory is allocated using the buddy system. a. Show the results of the following sequence in a figure similar to Figure 7.6: Request 70; Request 35; Request 80; Return A; Request 60; Return B; Return D; Return C. b. Show the binary tre
> This diagram shows an example of memory configuration under dynamic partitioning, after a number of placement and swapping-out operations have been carried out. Addresses go from left to right; gray areas indicate blocks occupied by processes; white area
> Another placement algorithm for dynamic partitioning is referred to as worst-fit. In this case, the largest free block of memory is used for bringing in a process. a. Discuss the pros and cons of this method compared to first- , next-, and best-fit. b. W
> To implement the various placement algorithms discussed for dynamic partitioning, a list of the free blocks of memory must be kept. For each of the three methods discussed (best-fit, first-fit, next-fit), what is the average length of the search?
> Consider a dynamic partitioning scheme. Show that, on average, the memory contains half as many holes as segments.
> Consider a fixed partitioning scheme with equal-size partitions of bytes and a total main memory size of 224 bytes. A process table is maintained that includes a pointer to a partition for each resident process. How many bits are required for the pointer
> Explain the difference between a monolithic kernel and a microkernel.
> It should be possible to implement general semaphores using binary semaphores. We can use the operations semWaitB and semSignalB and two binary semaphores, delay and mutex. Consider the following: Initially, (s) is set to the desired semaphore value. Ea
> Now consider another correct solution to the preceding problem: a. Explain how this program works and why it is correct. b. Does this solution differ from the preceding one in terms of the number of processes that can be unblocked at a time? Explain. c.
> Now consider this correct solution to the preceding problem: a. Explain how this program works and why it is correct. b. This solution does not completely prevent newly arriving processes from cutting in line but it does make it less likely. Give an exa
> Consider the following ways of handling deadlock: (1) banker’s algorithm, (2) detect deadlock and kill thread, releasing all resources, (3) reserve all resources in advance, (4) restart thread and release all resources if thread needs to wait, (5) r
> Consider a memory in which contiguous segments S1, S2, …, Sn are placed in their order of creation from one end of the store to the other, as suggested by the following figure: When segment Sn+1 is being created, it is placed immediat
> Consider a simple segmentation system that has the following segment table: / For each of the following logical addresses, determine the physical address or indicate if a segment fault occurs: a. 0, 198 b. 2, 156 c. 1, 530 d. 3, 444 e. 0, 222
> Write the binary translation of the logical address 0001010010111010 under the following hypothetical memory management schemes, and explain your answer: a. A paging system with a 256-address page size, using a page table in which the frame number happe

