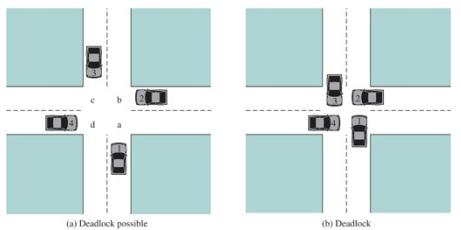
Question: Show how each of the techniques of
Show how each of the techniques of prevention, avoidance, and detection can be applied to Figure 6.1.
Figure 6.1:
Transcribed Image Text:
(a) Deadlock possible (b) Deadlock
> Prove that, among nonpreemptive scheduling algorithms, SPN provides the minimum average waiting time for a batch of jobs that arrive at the same time. Assume the scheduler must always execute a task if one is available.
> Consider the following set of processes: Perform the same analysis as depicted in Table 9.5 and Figure 9.5 for this set. Table 9.5: Figure 9.5: Process Arrival Time Processing Time A 3 В 1 3 D E 12 5 2. Table 9.5 A Comparison of Scheduling Policies
> Consider the following workload: a. Show the schedule using shortest remaining time, non preemptive priority (a smaller priority number implies higher priority) and round robin with quantum 30 ms. Use time scale diagram as shown below for the FCFS examp
> The IBM System/370 architecture uses a two-level memory structure and refers to the two levels as segments and pages, although the segmentation approach lacks many of the features described earlier in this chapter. For the basic 370 architecture, the pag
> Suppose the program statement is executed in a memory with page size of 1,000 words. Let n=1,000.Using a machine that has a full range of register-to-register instructions and employs index registers, write a hypothetical program to implement the forego
> In the VAX, user page tables are located at virtual addresses in the system space. What is the advantage of having user page tables in virtual rather than main memory? What is the disadvantage?
> A process contains eight virtual pages on disk and is assigned a fixed allocation of four page frames in main memory. The following page trace occurs: 1, 0, 2, 2, 1, 7, 6, 7, 0, 1, 2, 0, 3, 0, 4, 5, 1, 5, 2, 4, 5, 6, 7, 6, 7, 2, 4, a. Show the successive
> List the key design issues for an SMP operating system.
> A process references five pages, A, B, C, D, and E, in the following order: A; B; C; D; A; B; E; A; B; C; D; E Assume the replacement algorithm is first-in-first-out and find the number of page transfers during this sequence of references starting with a
> Consider the following string of page references 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2. C[ i, j ]=A[ i, j ]+B[ i, j ] Complete a figure similar to Figure 8.14, showing the frame allocation for: a. FIFO (first-in-first-out) b. LRU (least recently used) c.
> a. How much memory space is needed for the user page table of Figure 8.3 ? b. Assume you want to implement a hashed inverted page table for the same addressing scheme as depicted in Figure 8.3 , using a hash function that maps the 20-bit page number into
> Consider the following program. Assume the program is running on a system using demand paging, and the page size is 1 kB. Each integer is 4 bytes long. It is clear that each array requires a 16-page space. As an example, A[0, 0]-A[0, 63], A[1, 0]-A[1, 6
> A key to the performance of the VSWS resident set management policy is the value of Q. Experience has shown that with a fixed value of Q for a process, there are considerable differences in page fault frequencies at various stages of execution. Furthermo
> Consider the following sequence of page references (each element in the sequence represents a page number): 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 Define the mean working set size after the kth reference as sk(Δ)=1k ∑t=1k|W
> In the S/370 architecture, a storage key is a control field associated with each page-sized frame of real memory. Two bits of that key that are relevant for page replacement are the reference bit and the change bit. The reference bit is set to 1 when any
> In discussing a page replacement algorithm, one author makes an analogy with a snowplow moving around a circular track. Snow is falling uniformly on the track, and a lone snowplow continually circles the track at constant speed. The snow that is plowed o
> Consider a page reference string for a process with a working set of M frames, initially all empty. The page reference string is of length P with N distinct page numbers in it. For any page replacement algorithm, a. What is a lower bound on the number of
> Consider a system with memory mapping done on a page basis and using a single-level page table. Assume the necessary page table is always in memory. a. If a memory reference takes 200 ns, how long does a paged memory reference take? b. Now we add an MM
> What is multithreading?
> Assuming a page size of 4 kB and that a page table entry takes 4 bytes, how many levels of page tables would be required to map a 64-bit address space, if the top-level page table fits into a single page?
> Suppose the page table for the process currently executing on the processor looks like the following. All numbers are decimal, everything is numbered starting from zero, and all addresses are memory byte addresses. The page size is 1,024 bytes. a. Descr
> Let buddyk(x) = address of the buddy of the block of size 2k whose address is x. Write a general expression for buddyk(x).
> Consider a buddy system in which a particular block under the current allocation has an address of 011011110000. a. If the block is of size 4, what is the binary address of its buddy? b. If the block is of size 16, what is the binary address of its buddy
> A 1-Mbyte block of memory is allocated using the buddy system. a. Show the results of the following sequence in a figure similar to Figure 7.6: Request 70; Request 35; Request 80; Return A; Request 60; Return B; Return D; Return C. b. Show the binary tre
> This diagram shows an example of memory configuration under dynamic partitioning, after a number of placement and swapping-out operations have been carried out. Addresses go from left to right; gray areas indicate blocks occupied by processes; white area
> Another placement algorithm for dynamic partitioning is referred to as worst-fit. In this case, the largest free block of memory is used for bringing in a process. a. Discuss the pros and cons of this method compared to first- , next-, and best-fit. b. W
> To implement the various placement algorithms discussed for dynamic partitioning, a list of the free blocks of memory must be kept. For each of the three methods discussed (best-fit, first-fit, next-fit), what is the average length of the search?
> Consider a dynamic partitioning scheme. Show that, on average, the memory contains half as many holes as segments.
> Consider a fixed partitioning scheme with equal-size partitions of bytes and a total main memory size of 224 bytes. A process table is maintained that includes a pointer to a partition for each resident process. How many bits are required for the pointer
> Explain the difference between a monolithic kernel and a microkernel.
> It should be possible to implement general semaphores using binary semaphores. We can use the operations semWaitB and semSignalB and two binary semaphores, delay and mutex. Consider the following: Initially, (s) is set to the desired semaphore value. Ea
> Now consider another correct solution to the preceding problem: a. Explain how this program works and why it is correct. b. Does this solution differ from the preceding one in terms of the number of processes that can be unblocked at a time? Explain. c.
> Now consider this correct solution to the preceding problem: a. Explain how this program works and why it is correct. b. This solution does not completely prevent newly arriving processes from cutting in line but it does make it less likely. Give an exa
> Consider the following ways of handling deadlock: (1) banker’s algorithm, (2) detect deadlock and kill thread, releasing all resources, (3) reserve all resources in advance, (4) restart thread and release all resources if thread needs to wait, (5) r
> Consider a memory in which contiguous segments S1, S2, …, Sn are placed in their order of creation from one end of the store to the other, as suggested by the following figure: When segment Sn+1 is being created, it is placed immediat
> Consider a simple segmentation system that has the following segment table: / For each of the following logical addresses, determine the physical address or indicate if a segment fault occurs: a. 0, 198 b. 2, 156 c. 1, 530 d. 3, 444 e. 0, 222
> Write the binary translation of the logical address 0001010010111010 under the following hypothetical memory management schemes, and explain your answer: a. A paging system with a 256-address page size, using a page table in which the frame number happe
> Consider a simple paging system with the following parameters: 232 bytes of physical memory; page size of 210 bytes; 216 pages of logical address space. a. How many bits are in a logical address? b. How many bytes are in a frame? c. How many bits in the
> During the course of execution of a program, the processor will increment the contents of the instruction register (program counter) by one word after each instruction fetch, but will alter the contents of that register if it encounters a branch or call
> The Fibonacci sequence is defined as follows: F0=0, F1=1, Fn+2=Fn+1+Fn, n≥0 a. Could this sequence be used to establish a buddy system? b. What would be the advantage of this system over the binary buddy system described in this chapter?
> Describe the round-robin scheduling technique.
> In Section 2.3, we listed five objectives of memory management, and in Section 7.1, we listed five requirements. Argue that each list encompasses all of the concerns addressed in the other. Data from Section 2.3: 1. Process isolation: The OS must preven
> In the THE multiprogramming system [DIJK68], a drum (precursor to the disk for secondary storage) is divided into input buffers, processing areas, and output buffers, with floating boundaries, depending on the speed of the processes involved. The current
> Suggest an additional resource constraint that will prevent the deadlock in Problem 6.7, but still permit the boundary between input and output buffers to vary in accordance with the present needs of the processes.
> A spooling system (see Figure 6.17) consists of an input process I, a user process P, and an output process O connected by two buffers. The processes exchange data in blocks of equal size. These blocks are buffered on a disk using a floating boundary bet
> In the code below, three processes are competing for six resources labeled A to F. a. Using a resource allocation graph (see Figures 6.5 and 6.6), show the possibility of a deadlock in this implementation. b. Modify the order of some of the get requests
> Given the following state for the Banker’s Algorithm: 6 processes P0 through P5 4 resource types: A (15 instances); B (6 instances) C (9 instances); D (10 instances) Snapshot at time T0: The first four columns of the 68 matrix compris
> It was stated that deadlock cannot occur for the situation reflected in Figure 6.3. Justify that statement. Figure 6.3: Progress of Q Release Release B Pand Q want A Required Pand Q want B Get A B Required Get B Progress of P Get A Release A Get B R
> For Figure 6.3, provide a narrative description of each of the six depicted paths, similar to the description of the paths of Figure 6.2 provided in Section 6.1. Figure 6.3: Figure 6.2: Progress of Q Release Release B Pand Q want A Required Pand Q
> Consider a system consisting of four processes and a single resource. The current state of the claim and allocation matrices are: C= (3297) A= (1132) What is the minimum number of units of the resource needed to be available for this state to be safe?
> Explain the distinction between a real address and a virtual address.
> Suppose the following two processes, foo and bar, are executed concurrently and share the semaphore variables S and R (each initialized to 1) and the integer variable x (initialized to 0). a. Can the concurrent execution of these two processes result in
> A pipeline algorithm is implemented so a stream of data elements of type T produced by a process P0 passes through a sequence of processes P1, P2, …, Pn−1, which operates on the elements in that order. a. Define a generalized message buffer that contains
> Evaluate the banker’s algorithm for its usefulness in an OS.
> Consider a system with a total of 150 units of memory, allocated to three processes as shown: Apply the banker’s algorithm to determine whether it would be safe to grant each of the following requests. If yes, indicate a sequence of te
> In the THE multiprogramming system, a page can make the following state transitions: a. Define the effect of these transitions in terms of the quantities i, o, and p. b. Can any of them lead to a deadlock if the assumptions made in Problem 6.6 about inp
> Show that the four conditions of deadlock apply to Figure 6.1a. Figure 6.1a: (a) Deadlock possible
> Consider the following program: This software solution to the mutual exclusion problem for two processes is proposed in [HYMA66]. Find a counterexample that demonstrates that this solution is incorrect. It is interesting to note that even the Communicat
> Is busy waiting always less efficient (in terms of using processor time) than a blocking wait? Explain.
> Consider the following program: a. Determine the proper lower bound and upper bound on the final value of the shared variable tally output by this concurrent program. Assume processes can execute at any relative speed, and a value can only be incremente
> Consider the following program: Note the scheduler in a uniprocessor system would implement pseudo-parallel execution of these two concurrent processes by interleaving their instructions, without restriction on the order of the interleaving. a. Show a s
> List and briefly explain five storage management responsibilities of a typical OS.
> Processes and threads provide a powerful structuring tool for implementing programs that would be much more complex as simple sequential programs. An earlier construct that is instructive to examine is the coroutine. The purpose of this problem is to int
> At the beginning of Section 5.2, it is stated that multiprogramming and multiprocessing present the same problems, with respect to concurrency. This is true as far as it goes. However, cite two differences in terms of concurrency between multiprogramming
> Demonstrate that the following software approaches to mutual exclusion do not depend on elementary mutual exclusion at the memory access level: a. The bakery algorithm. b. Peterson’s algorithm.
> Consider Dekker’s algorithm written for an arbitrary number of processes by changing the statement executed when leaving the critical section from Evaluate the algorithm when the number of concurrently executing processes is greater tha
> Consider a sharable resource with the following characteristics: (1) As long as there are fewer than three processes using the resource, new processes can start using it right away. (2) Once there are three process using the resource, all three must le
> Consider the following definition of semaphores: Compare this set of definitions with that of Figure 5.6. Note one difference: With the preceding definition, a semaphore can never take on a negative value. Is there any difference in the effect of the tw
> When a special machine instruction is used to provide mutual exclusion in the fashion of Figure 5.5, there is no control over how long a process must wait before being granted access to its critical section. Devise an algorithm that uses the compare &
> Consider the first instance of the statement / in Figure 5.5b. Figure 5.5b: a. Achieve the same result using the exchange instruction. b. Which method is preferable?
> Consider the following program which provides a software approach to mutual exclusion: Where 1≤k≤N, and each element of “control” is either 0, 1, or 2. All elements of â&#
> Now consider a version of the bakery algorithm without the variable choosing. Then we have Does this version violate mutual exclusion? Explain why or why not. 1 int number [n]; 2 while (true) { number [i] = 1 + getmax (number [], n); 4 for (intj =
> How is the execution context of a process used by the OS?
> A software approach to mutual exclusion is Lamport’s bakery algorithm [LAMP74], so called because it is based on the practice in bakeries and other shops in which every customer receives a numbered ticket on arrival, allowing each to be
> Demonstrate the correctness of Dekker’s algorithm. a. Show that mutual exclusion is enforced. Hint: Show that when Pi enters its critical section, the following expression is true: b. Show that a process requiring access to its critical
> Consider the following code using the POSIX Pthreads API: In / we first declare a variable called mythread, which has a type of /. This is essentially an ID for a thread. Next, the / statement creates a thread associated with /. The call returns zero on
> But some existing optimizing compilers (including gcc, which tends to be relatively conservative) will “optimize” / to something similar to What problem or potential problem occurs with this compiled version of the pr
> Many current language specifications, such as for C and are inadequate for multithreaded programs. This can have an impact on compilers and the correctness of code, as this problem illustrates. Consider the following declarations and function definition:
> The OS/390 mainframe operating system is structured around the concepts of address space and task. Roughly speaking, a single address space corresponds to a single application and corresponds more or less to a process in other operating systems. Within a
> If a process exits and there are still threads of that process running, will they continue to run?
> Consider an environment in which there is a one-to-one mapping between user-level threads and kernel-level threads that allows one or more threads within a process to issue blocking system calls while other threads continue to run. Explain why this model
> OS/2 from IBM is an obsolete OS for PCs. In OS/2, what is commonly embodied in the concept of process in other operating systems is split into three separate types of entities: session, processes, and threads. A session is a collection of one or more pro
> In virtually all systems that include DMA modules, DMA access to main memory is given higher priority than processor access to main memory. Why?
> What is a process?
> Consider a computer system that contains an I/O module controlling a simple keyboard/printer Teletype. The following registers are contained in the CPU and connected directly to the system bus: INPR: Input Register, 8 bits OUTR: Output Register, 8 bits F
> In IBM’s mainframe OS, OS/390, one of the major modules in the kernel is the System Resource Manager. This module is responsible for the allocation of resources among address spaces (processes). The SRM gives OS/390 a degree of sophistication unique amon
> What is the purpose of system calls, and how do system calls relate to the OS and to the concept of dual-mode (kernel-mode and user-mode) operation?
> Contrast the scheduling policies you might use when trying to optimize a time-sharing system with those you would use to optimize a multiprogrammed batch system.
> An I/O-bound program is one that, if run alone, would spend more time waiting for I/O than using the processor. A processor-bound program is the opposite. Suppose a short-term scheduling algorithm favors those programs that have used little processor tim
> Consider a memory system with the following parameters: Tc=100 ns Cc=0.01 cents/bitTm=1,200 ns Cm=0.001 cents/bit a. What is the cost of 1 MByte of main memory? b. What is the cost of 1 MByte of main memory using cache memory technology? c. If the effect
> Suppose the hypothetical processor of Figure 1.3 also has two I/O instructions: 0011=Load AC from I/O0111 =Store AC to I/O. In these cases, the 12-bit address identifies a particular external device. Show the program execution (using the format of Figure
> Consider the following code: a. Give one example of the spatial locality in the code. b. Give one example of the temporal locality in the code. for (i = 0; i < 20; i++) for (j = 0; j < 10; j++) %3D a[i] = a[i] * j
> In the discussion of ULTs versus KLTs, it was pointed out that a disadvantage of ULTs is that when a ULT executes a system call, not only is that thread blocked, but also all of the threads within the process are blocked. Why is that so?
> Suppose we have a multiprogrammed computer in which each job has identical characteristics. In one computation period, T, for a job, half the time is spent in I/O, and the other half in processor activity. Each job runs for a total of N periods. Assume a
> What is multiprogramming?
> Consider a 32-bit microprocessor, with a 16-bit external data bus, driven by an 8-MHz input clock. Assume this microprocessor has a bus cycle whose minimum duration equals four input clock cycles. What is the maximum data transfer rate across the bus tha
> Consider a hypothetical microprocessor generating a 16-bit address (e.g., assume the program counter and the address registers are 16 bits wide) and having a 16-bit data bus. a. What is the maximum memory address space that the processor can access di
> Consider a hypothetical 32-bit microprocessor having 32-bit instructions composed of two fields. The first byte contains the opcode, and the remainder an immediate operand or an operand address. a. What is the maximum directly addressable memory capacity
> The program execution of Figure 1.4 is described in the text using six steps. Expand this description to show the use of the MAR and MBR. Figure 1.4: Fetch stage Execute stage Memory 300 I9 4 0 301 5 9 4 I 302 29 4 1 CPU registers 300 PC Meтory 300I
> Suppose a stack is to be used by the processor to manage procedure calls and returns. Can the program counter be eliminated by using the top of the stack as a program counter?

