Question: The U.S. Commodities Futures Trading Commission
The U.S. Commodities Futures Trading Commission reports on the volume of trading in the U.S. commodity futures exchanges. Shown here are the figures for grain, oilseeds, and livestock products over a period of several years. Use these data to develop a multiple regression model to predict grain futures volume of trading from oilseeds volume and livestock products volume. All figures are given in units of millions. Graph each of these predictors separately with the response variable and use Tukey’s four-quadrant approach to explore possible recoding schemes for nonlinear relationships. Include any of these in the regression model. Comment on the results.
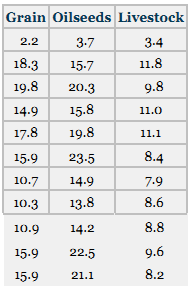
> Solve for the predicted values of y and the residuals for the data in Problem 12.9. The data are provided here again.
> Shown here are retail price figures and quantity estimates for five different food commodities over 3 years. Use these data and a base year of 2017 to compute unweighted aggregate price indexes for this market basket of food. Using a base year of 2017, c
> Determine the trend for the data in Problem 15.32 using the deseasonalized data from Problem 15.33. Explore both a linear and a quadratic model in an attempt to develop the better trend model. Refer to the Problem Data 15.32-15.33: Time Period ________
> Use the seasonal indexes computed to deseasonalize the data in Problem 15.32. Refer to the Problem Data 15.32: Time Period ________________ Chemicals and Allied Products ($ billions) January (year 5) ……â
> The U.S. Department of Commerce publishes a series of census documents referred to as Current Industrial Reports. Included in these documents are the manufacturers’ shipments, inventories, and orders over a 5-year period. Displayed here
> The following data contain the quantity (million pounds) of U.S. domestic fish caught annually over a 25- year period as published by the National Oceanic and Atmospheric Administration. a) Use a 3-year moving average to forecast the quantity of fish for
> Using the following data and 2016 as the base year, compute the Laspeyres price index for 2019 and the Paasche price index for 2018.
> Using the following data, determine the values of MAD and MSE. Which of these measurements of error seems to yield the best information about the forecasts? Why?
> Compute unweighted aggregate price index numbers for each of the given years using 2015 as the base year.
> Compute index numbers for the following data using 2000 as the base year.
> Following are the average yields of long-term new corporate bonds over a several-month period published by the Office of Market Finance of the U.S. Department of the Treasury. a) Explore trends in these data by using regression trend analysis. How stron
> Solve for the predicted values of y and the residuals for the data in Problem 12.8. The data are provided here again.
> Calculate Paasche price indexes for 2017 and 2018 using the following data and 2005 as the base year.
> Calculate Laspeyres price indexes for 2016–2018 from the following data. Use 2005 as the base year.
> Suppose the following data are prices of market goods involved in household transportation for the years 2011 through 2018. Using 2013 as a base year, compute aggregate transportation price indexes for this data.
> Using the data that follow, compute the aggregate index numbers for the four types of meat. Let 1995 be the base year for this market basket of goods.
> The U.S. Patent and Trademark Office reports fiscal year figures for patents issued in the United States. Following are the numbers of patents issued for the years 1980 through 2015. Using these data and a base year of 1990, determine the simple index nu
> Suppose the following data represent the price of 20 reams of office paper over a 65-year time frame. Find the simple index numbers for the data. a) Let 1950 be the base year. b) Let 1980 be the base year.
> The U.S. Department of Agriculture publishes data on the production, utilization, and value of fruits in the United States. Shown here are the amounts of non-citrus fruit processed into juice (in kilotons) for a 25-year period. Use these data to develop
> Determine the error for each of the following forecasts. Compute MAD and MSE.
> Current Construction Reports from the U.S. Census Bureau contain data on new privately owned housing units. Data on new privately owned housing units (1000s) built in the West over a 31-year period follow. Use these time-series data to develop an auto-re
> Use the data in Problem 15.17 to compute a regression model after recoding the data by the first-differences approach. Compute a Durbin-Watson statistic to determine whether significant autocorrelation is present in this first-differences model. Compare
> Solve for the predicted values of y and the residuals for the data in Problem 12.7. The data are provided here again.
> The Federal Deposit Insurance Corporation (FDIC) releases data on bank failures. Following are data on the number of U.S. bank failures in a given year and the total amount of bank deposits (in $ millions) involved in such failures for a given year. Use
> Use the data from Problem 15.15 to create a regression forecasting model using the first-differences data transformation. How do the results from this model differ from those obtained in Problem 15.15? Refer to the Problem Data 15.15:
> The U.S. Department of Labor publishes consumer price indexes (CPIs) on many commodities. Following are the percentage changes in the CPIs for food and for shelter for the years 2001 through 2018. Use these data to develop a linear regression model to fo
> The U.S. Department of Commerce publishes census information on manufacturing. Included in these figures are monthly shipment data for the paperboard container and box industry shown below for 6 years. The shipment figures are given in millions of dollar
> The U.S. Department of Agriculture publishes statistics on the production of various types of food commodities by month. Shown here are the production figures on broccoli for January of a recent year through December of the next year. Use these data to c
> Shown below are dollar figures for commercial and industrial loans at all commercial banks in the United States as recorded for the month of April during a recent 9-year period and published by the Federal Reserve Bank of St. Louis. Plot the data, fit a
> The following data on the number of union members in the United States for the years 1986 through 2018 are provided by the U.S. Bureau of Labor Statistics. Using regression techniques discussed in this section, analyze the data for trend. Develop a scatt
> The “Economic Report to the President of the United States” included data on the amounts of manufacturers’ new and unfilled orders in millions of dollars. Shown here are the figures for new orders ove
> Use the forecast errors given here to compute MAD and MSE. Discuss the information yielded by each type of error measurement. Period ______________ e 1 ………………………………… 2.3 2 ………………………………… 1.6 3 ………………………………. −1.4 4 ……...…………………………. 1.1 5 ……...………………………… 0.
> The Minitab output displayed here is the result of a multiple regression analysis with three independent variables. Variable x1 is a dummy variable. Discuss the computer output and the role x1 plays in this regression model. Analysis of Variance Coeffic
> Solve for the predicted values of y and the residuals for the data in Problem 12.6. The data are provided here again.
> Given here are the data from a dependent variable and two independent variables. The second independent variable is an indicator variable with several categories. Hence, this variable is represented by x2, x3, and x4. How many categories are there for th
> Analyze the following data by using a multiple regression computer software package to predict y using x1 and x2. Notice that x2 is a dummy variable. Discuss the output from the regression analysis; in particular, comment on the predictability of the dum
> What follows is Excel output from a regression model to predict y using x1, x2, x21, x22, and the interaction term, x1x2. Comment on the overall strength of the model and the significance of each predictor. The data follow the Excel output. Develop a reg
> Use the following data to develop a curvilinear model to predict y. Include both x1 and x2 in the model in addition to x21 and x22, and the interaction term x1x2. Comment on the overall strength of the model and the significance of each predictor. Develo
> Dun & Bradstreet reports, among other things, information about new business incorporations and number of business failures over several years. Shown here are data on business failures and current liabilities of the failing companies over several years.
> Shown below is Minitab output from a logistic regression analysis to develop a model to predict whether a shopper in a mall store will purchase something by the number of miles the shopper drives to get to the mall store. The original data were coded as
> Shown below is output from two Excel regression analyses on the same problem. The first output was done on a “full” model. In the second output, the variable with the smallest absolute t value has been removed, and the
> Shown here are the data for y and three predictors, x1, x2, and x3. A stepwise regression procedure has been done on these data; the results are also given. Comment on the outcome of the stepwise analysis in light of the data. Candidate terms: X1, X2, X
> A stepwise regression procedure was used to analyze a set of 20 observations taken on four predictor variables to predict a dependent variable. The results of this procedure are given next. Discuss the results. Candidate terms: X1, X2, X3, X4
> The American Chamber of Commerce Researchers Association compiles cost-of-living indexes for selected metropolitan areas. Shown here are cost-of-living indexes for 25 different cities on five different items for a recent year. Use the data to develop a r
> Determine the equation of the regression line for the following data, and compute the residuals.
> The U.S. Department of Agriculture publishes data annually on various selected farm products. Shown here are the unit production figures for three farm products for 10 years during a 20-year period. Use these data and a stepwise regression analysis to pr
> The U.S. Bureau of Labor Statistics produces consumer price indexes for several different categories. Shown here are the percentage changes in consumer price indexes over a period of 20 years for food, shelter, apparel, and fuel oil. Also displayed are t
> The Shipbuilders Council of America in Washington, D.C., publishes data about private shipyards. Among the variables reported by this organization are the employment figures (per 1000), the number of naval vessels under construction, and the number of re
> The U.S. Bureau of Mines produces data on the price of minerals. Shown here are the average prices per year for several minerals over a decade. Use these data and a stepwise regression procedure to produce a model to predict the average price of gold fro
> The Publishers Information Bureau in New York City released magazine advertising expenditure data compiled by leading national advertisers. The data were organized by product type over several years. Shown here are data on total magazine advertising expe
> Use the x1 values and the log of the x1 values given here to predict the y values by using a stepwise regression procedure. Discuss the output. Were either or both of the predictors significant?
> Use the following data and a stepwise regression analysis to predict y. In addition to the two independent variables given here, include three other predictors in your analysis: the square of each x as a predictor and an interaction predictor. Discuss th
> Given here are the data for a dependent variable, y, and independent variables. Use these data to develop a regression model to predict y. Discuss the output. Which variable is an indicator variable? Was it a significant predictor of y?
> The World’s Largest Companies database contains information on four variables: Sales, Profits, Assets, and Market Value for the 1700 largest companies in the world. There is an additional variable that displays the country in which the
> Can the annual new orders for manufacturing in the United States be predicted by the raw steel production in the United States? Shown below are the annual new orders for 10 years according to the U.S. Census Bureau and the raw steel production for the sa
> The Manufacturing database associated with this text and found in WileyPLUS has a variable, Value of Industrial Shipments that is coded 0 if the value is small and 1 if the value is large. Using Minitab, a logistic regression analysis was done in an atte
> A database associated with this text and found in WileyPLUS is the Consumer Food database. There is a dichotomous variable in this database, and that is whether a family lives in a metro area or outside. In the database, metro is coded as 1 and outside m
> A hospital database contains a dichotomous variable, Service, that represents two types of hospitals, general medical and psychiatric. In the database, general medical hospitals are coded as 1 and psychiatric hospitals as 2. However, to run a logistic re
> Study the three predictor variables in Problem 14.18 and attempt to determine whether substantial multi-collinearity is present among the predictor variables. If there is a problem of multi-collinearity, how might it affect the outcome of the multiple re
> In Problem 14.17, you were asked to use stepwise regression to predict premiums earned by net income, dividends, and underwriting gain or loss. Study the stepwise results, including the regression coefficients, to determine whether there may be a problem
> Construct a correlation matrix for the four independent variables for Problem 14.14 and search for possible multi-collinearity. What did you find, and why? Refer to the Problem Data 14.14:
> Develop a multiple regression model of the form y = b0bx1 ( Using the following data to predict y from x. From a scatter plot and Tukey’s ladder of transformation, explore ways to recode the data and develop an alternative regression mo
> Develop a correlation matrix for the independent variables in Problem 14.13. Study the matrix and make a judgment as to whether substantial multi-collinearity is present among the predictors. Why or why not?
> The U.S. Energy Information Administration releases figures in their publication, Monthly Energy Review, about the cost of various fuels and electricity. Shown here are the figures for four different items over a 12-year period. Use the data and stepwise
> The National Underwriter Company in Cincinnati, Ohio, publishes property and casualty insurance data. Given here is a portion of the data published. These data include information from the U.S. insurance industry about (1) net income after taxes, (2) div
> It appears that over the past 50 years, the number of farms in the United States declined while the average size of farms increased. The following data provided by the U.S. Department of Agriculture show five-year interval data for U.S. farms. Use these
> Study the output given here from a stepwise multiple regression analysis to predict y from four variables. Comment on the output at each step. Stepwise Selection of Terms
> The computer output given here is the result of a stepwise multiple regression analysis to predict a dependent variable by using six predictor variables. The number of observations was 108. Study the output and discuss the results. How many predictors en
> Given here are data for a dependent variable and four potential predictors. Use these data and a stepwise regression procedure to develop a multiple regression model to predict y. Examine the values of t and R2 at each step and comment on those values. H
> Use a stepwise regression procedure and the following data to develop a multiple regression model to predict y. Discuss the variables that enter at each step, commenting on their t values and on the value of R2.
> A researcher gathered 155 observations on four variables: job satisfaction, occupation, industry, and marital status. She wants to develop a multiple regression model to predict job satisfaction by the other three variables. All three predictor variables
> Falvey, Fried, and Richards developed a multiple regression model to predict the average price of a meal at New Orleans restaurants. The variables explored included such indicator variables as the following: Accepts reservations, Has its own parking lot,
> Given here is Excel output for a multiple regression model that was developed to predict y from two independent variables, x1 and x2. Variable x2 is a dummy variable. Discuss the strength of the multiple regression model on the basis of the output. Focus
> Use the following data to develop a quadratic model to predict y from x. Develop a simple regression model from the data and compare the results of the two models. Does the quadratic model seem to provide any better predictability? Why or why not?
> Using the data in Problem 13.5, develop a multiple regression model to predict per capita personal consumption by the consumption of paper, fish, and gasoline. Discuss the output and pay particular attention to the F test and the t tests. Refer to the P
> Displayed here is the Minitab output for a multiple regression analysis. Study the ANOVA table and the t ratios and use these to discuss the strengths of the regression model and the predictors. Does this model appear to fit the data well? From the infor
> Is it possible to predict the annual number of business bankruptcies by the number of firm births (business starts) in the United States? The following data, published by the U.S. Small Business Administration, Office of Advocacy, are pairs of the number
> Determine the value of the coefficient of correlation, r, for the following data.
> Let X be a continuous random variable with values between A = 1 and B = ∞, and with the density function f (x) = 4x-5. Compute E(X ) and Var (X ).
> The amount of milk (in thousands of gallons) that a dairy sells each week is a random variable X with the density function f (x) = 4(x - 1)3, 1 ≤ x ≤ 2. (See Fig. 4.) (a) What is the likelihood that the dairy will
> When preparing a bid on a large construction project, a contractor analyzes how long each phase of the construction will take. Suppose that the contractor estimates that the time required for the electrical work will be X hundred worker-hours, where X is
> At a certain bus stop the time between buses is a random variable X with the density function f (x) = 6x(10 - x)/1000, 0 ≤ x ≤ 10. Find the average time between buses.
> The amount of time (in minutes) that a person spends reading the editorial page of the newspaper is a random variable with the density function f (x) = 1/72 x, 0 ≤ x ≤ 12. Find the average time spent reading the editorial page.
> The time (in minutes) required to complete an assembly on a production line is a random variable X with the cumulative distribution function F (x) = 1/125 x3, 0 ≤ x ≤ 5. (a) Find E(X ) and give an interpretation of this quantity. (b) Compute Var (X ).
> The useful life (in hundreds of hours) of a certain machine component is a random variable X with the cumulative distribution function F (x) = 1/9 x2, 0 ≤ x ≤ 3. (a) Find E(X ), and give an interpretation of this quantity. (b) Compute Var (X ).
> Let X be the proportion of new restaurants in a given year that make a profit during their first year of operation, and suppose that the density function for X is f (x) = 20x3(1 - x), 0 ≤ x ≤ 1. (a) Find E(X ) and give an interpretation of this quantity
> A newspaper publisher estimates that the proportion X of space devoted to advertising on a given day is a random variable with the beta probability density f (x) = 30x2(1 - x)2, 0 ≤ x ≤ 1. (a) Find the cumulative distribution function for X. (b) Find t
> Find the expected value and variance for each random variable whose probability density function is given. When computing the variance, use formula (5). f (x) = 3√x/16, 0 ≤ x ≤ 4
> The density function f (x) for the lifetime of a certain battery is shown in Fig. 1. Each battery lasts between 3 and 10 hours. (a) Sketch the graph of the corresponding cumulative distribution function F (x). (b) What is the meaning of the number F (7)
> Find the expected value and variance for each random variable whose probability density function is given. When computing the variance, use formula (5). f (x) = 12 x(1 - x)2, 0 ≤ x ≤ 1
> Find the expected value and variance for each random variable whose probability density function is given. When computing the variance, use formula (5). f (x) = 3/2 x – ¾ x2, 0 ≤ x ≤ 2
> Find the expected value and variance for each random variable whose probability density function is given. When computing the variance, use formula (5). f (x) = 5x4, 0 ≤ x ≤ 1
> Find the expected value and variance for each random variable whose probability density function is given. When computing the variance, use formula (5). f (x) = 8/9 x, 0 ≤ x ≤ 32
> Find the expected value and variance for each random variable whose probability density function is given. When computing the variance, use formula (5). f (x) = 1/4, 1 ≤ x ≤ 5
> Verify that each of the following functions is a probability density function. f (x) = 1/18 x, 0 ≤ x ≤ 6
> Find the value of k that makes the given function a probability density function on the specified interval. f (x) = k/√x, 1 ≤ x ≤ 4
> Find the value of k that makes the given function a probability density function on the specified interval. f (x) = k, 5 ≤ x ≤ 20
> Find the value of k that makes the given function a probability density function on the specified interval. f (x) = kx2, 0 ≤ x ≤ 2
> Find the value of k that makes the given function a probability density function on the specified interval. f (x) = kx, 1 ≤ x ≤ 3
> The annual incomes of the households in a certain community range between 5 and 25 thousand dollars. Let X represent the annual income (in thousands of dollars) of a household chosen at random in this community, and suppose that the probability density f

